NAS selber bauen 2026: Die vollständige Anleitung für dein Heimnetz-NAS
Ein selbst gebauter NAS auf Intel N100-Basis mit vier CMR-Festplatten, 2,5GbE-Switch und USV — das Fundament für ein zuverlässiges Heimnetz-NAS 2026.
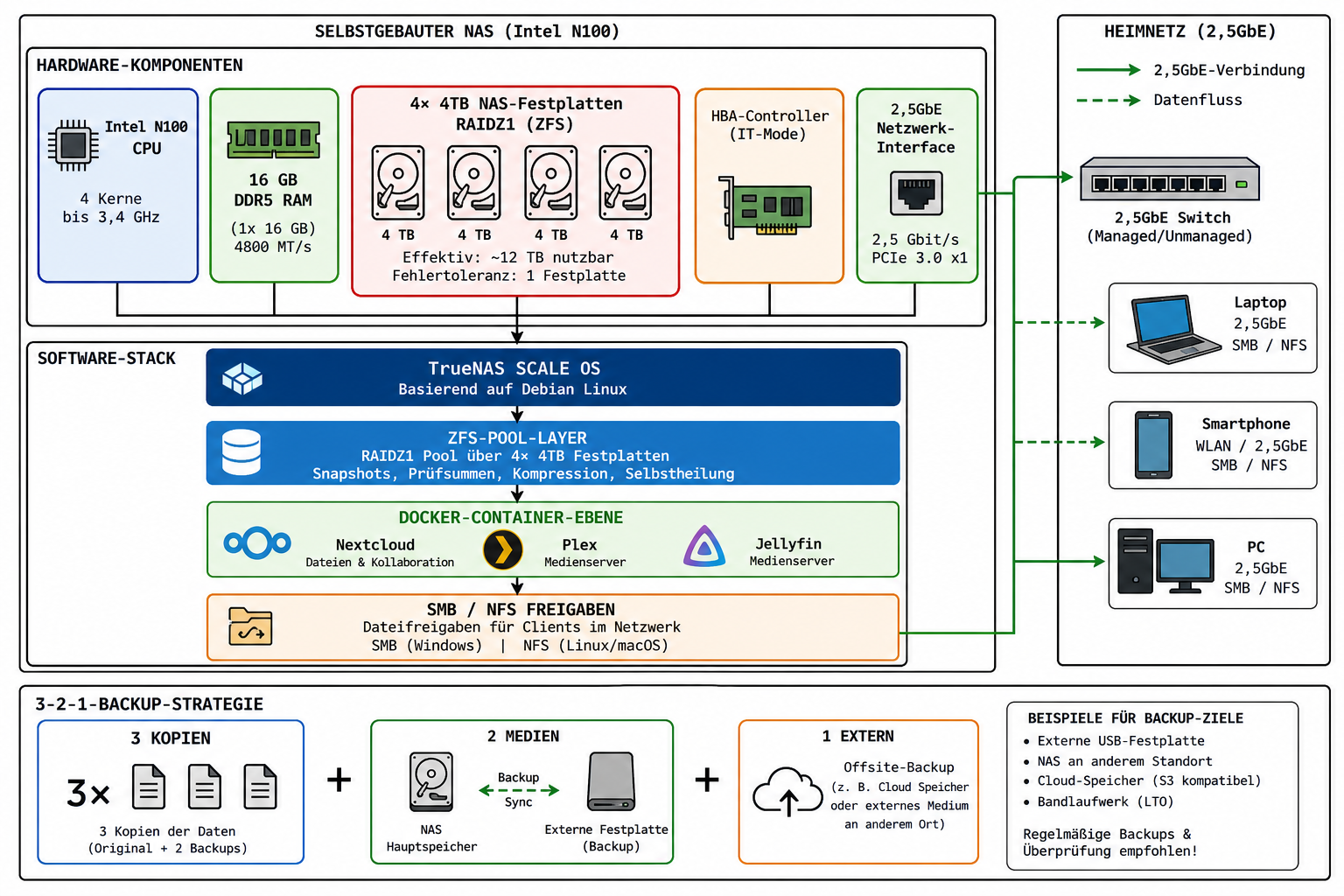
Wer einen zentralen Datenspeicher mit vollem Zugriff auf Hardware, Betriebssystem und Daten braucht, kommt 2026 an einem selbst gebauten NAS auf Intel N100-Basis kaum vorbei. ZFS-Redundanz, Docker-Container und 2,5GbE-Netzwerk lassen sich damit für unter 400 € realisieren — ohne Cloud-Zwang, ohne Lizenzfallen. Wichtige Einschränkung vorab: Wer 1–4 Festplatten ohne VMs oder Docker betreibt und keine Zeit für Troubleshooting investieren will, ist mit einer gebrauchten Synology DS423+ oft konkurrenzfähig im Gesamtpreis. Das ist keine Niederlage, sondern eine ehrliche Abwägung.
📑 Inhaltsverzeichnis
Und noch etwas, bevor wir anfangen: RAID ist kein Backup. Wir planen Redundanz und Datensicherung von Anfang an parallel — dazu mehr im Abschnitt zur 3-2-1-Strategie.
Warum ein selbst gebautes NAS 2026 Sinn ergibt — und wann nicht
Ein NAS selber bauen kostet 2026 bei 6+ Festplatten-Slots deutlich weniger als eine vergleichbare Fertiglösung — und liefert dabei mehr Flexibilität. Aus einem Intel-N100-Mini-PC, vier NAS-Festplatten und kostenloser Software entsteht ein zentraler Datenspeicher mit redundantem ZFS-Pool (RAIDZ1/RAIDZ2), SMB-Freigaben für alle Geräte im Heimnetz, einer eigenen Nextcloud, einem Plex- oder Jellyfin-Medienserver und einer sauberen 3-2-1-Backup-Strategie.
Wann Selbstbau sich lohnt — und wann nicht:
Szenario
Empfehlung
Begründung
6+ Festplatten, VMs, Docker
Selbstbau (N100 oder Xeon)
Fertiglösungen teuer, weniger flexibel
GPU-Transcoding (Plex/Jellyfin)
Selbstbau mit TrueNAS Scale
Synology/QNAP ohne GPU-Support
10GbE, NVMe-Caching, HBA
Selbstbau
Fertiglösungen unterstützen das nicht
1–4 Platten, reine NAS-Funktion
Synology/QNAP oder Selbstbau
Gesamtkosten oft vergleichbar
Kein Interesse an Troubleshooting
Synology DS423+
ARM-SoC, 15–20W, fertig konfiguriert
Typischer Anfängerfehler: Selbstbau ist immer günstiger als Synology oder QNAP. Bei kleinen Setups (1–4 Festplatten, reine NAS-Funktion) stimmt das nicht. Ein Synology DS423+ kostet ~400 €. Ein vergleichbarer Selbstbau mit Gehäuse, Board, CPU, RAM, HBA und USV-Kompatibilität landet schnell bei 350–500 €. Dazu kommen Stromkosten: Synology ARM-Prozessoren verbrauchen 15–20 W, ein schlecht optimierter x86-Selbstbau 40–80 W — bei 24/7-Betrieb über 5 Jahre macht das 200–400 € Unterschied. Selbstbau lohnt sich klar ab 6+ Bays, bei Bedarf nach VMs/Docker oder GPU-Transcoding.
Schwierigkeitsgrad: mittel. Grundlegende Linux-Kenntnisse und Kommandozeilen-Erfahrung werden vorausgesetzt.
Zeitplanung: Plane realistisch 2–3 Tage für einen vollständig konfigurierten und getesteten Build. SMR-Platten-Erkennung und Rückgabe/Ersatz kosten 1–3 Tage Versandzeit. BIOS-Updates bei N100-Boards dauern 30–60 Minuten. Der erste ZFS-Scrub bei 4× 4 TB läuft 3–5 Stunden. Die Nextcloud-Ersteinrichtung mit Datenbank-Migration braucht 1–2 Stunden.
Aufgefallen bei mehreren Setups: Auf Minisforum-N100-Boards (MS-01, UN100L) ist die BIOS-Versionsnummer entscheidend für die Stabilität des SATA-Controllers. Boards mit BIOS-Versionen vor 2024-Q2 zeigen unter Ubuntu 22.04 und Debian 12 sporadische SATA-Link-Resets (dmesg | grep "ata[0-9]: SATA link down"), die ZFS als Disk-Fehler interpretiert und den Pool in DEGRADED versetzt — obwohl die Platten physisch in Ordnung sind. Ein BIOS-Update löst das Problem vollständig; ohne Update hilft nur echo 1 > /sys/module/libata/parameters/noacpi.
Welches NAS-Betriebssystem für dein Setup passt: TrueNAS Scale, TrueNAS Core, Unraid oder OpenMediaVault
Die Wahl des Betriebssystems entscheidet über alles Weitere — und ein späterer Wechsel kann, wie wir gleich sehen werden, im schlimmsten Fall Daten kosten. Hier ist die Entscheidungsmatrix für 2026:
Kriterium
TrueNAS Core (FreeBSD)
TrueNAS Scale (Debian)
Unraid
OpenMediaVault 7
ZFS-Basis
OpenZFS (älter)
OpenZFS (aktuell)
Btrfs/XFS + ZFS optional
ZFS via Plugin
Docker-Support
Nein (Jails)
Ja (Apps/k3s)
Ja (Community Apps)
Ja (Compose-Plugin)
GPU-Passthrough
Eingeschränkt
Ja
Ja
Ja
SMB-Stabilität
Sehr gut
Gut (Regressionen bis 2025)
Gut
Gut
Lizenzkosten
Kostenlos
Kostenlos
59–129 $
Kostenlos
Ideal für
Reine NAS-Workloads
NAS + Docker + Plex
Gemischte Disk-Größen
Einsteiger, OMV-GUI
Intel N100 kompatibel
Ja
Ja
Ja
Ja
Wenn X → dann Y:
– Wenn du reine NAS-Funktion ohne Docker willst → TrueNAS Core
– Wenn du Docker + Jellyfin/Plex-Transcoding mit GPU brauchst → TrueNAS Scale
– Wenn du unterschiedliche Festplattengrößen mischen willst → Unraid
– Wenn du einen einfachen Einstieg mit GUI suchst → OpenMediaVault 7
– Wenn du Nextcloud auf TrueNAS Scale betreiben willst → TrueNAS Scale mit Docker Compose (nicht die k3s-App)
Typischer Anfängerfehler: TrueNAS Scale und TrueNAS Core sind dasselbe — nur mit anderem Unterbau. Die Unterschiede sind fundamental, und ein falscher Plattformwechsel kann zu Datenverlust führen. TrueNAS Core (FreeBSD/OpenZFS) nutzt eine ältere OpenZFS-Version. TrueNAS Scale (Debian/OpenZFS) nutzt eine neuere Version mit anderen Feature-Flags. Kritisch: Ein Pool, der unter Scale mit neueren OpenZFS-Feature-Flags erstellt wurde, kann unter Core nicht importiert werden. Prüfe vor einer Migration: zpool get all | grep feature — inkompatible Features machen den Pool auf Core unlesbar. TrueNAS Scale hat außerdem bis 2025 wiederholt Regressionen bei SMB-Multichannel und iSCSI gehabt. Erst Backup anlegen, dann migrieren.
TrueNAS Scale 24.x und Docker: TrueNAS Scale 24.x hat mit der Einführung von „Apps“ (basierend auf Kubernetes/k3s) die Docker-Verwaltung grundlegend geändert. Viele Nutzer haben nach dem Update auf 24.x ihre laufenden Docker-Container verloren, weil die Migration von Docker Compose zu k3s-Apps nicht automatisch funktioniert. Wer einfaches Docker Compose bevorzugt, ist mit OMV 7.x + dem Compose-Plugin besser bedient.
Diese Anleitung verwendet OpenMediaVault 7 auf einem Intel N100-Board als Basis — weil es die niedrigste Einstiegshürde hat und Docker Compose nativ unterstützt. Die ZFS-Befehle und Docker-Konfigurationen gelten identisch für TrueNAS Scale.
Wichtig zu wissen: Auf QNAP QTS 5.x läuft Docker über die „Container Station“-App, die intern eine modifizierte Docker-Engine verwendet. Diese ist gegenüber dem upstream Docker-Release typischerweise 2–4 Versionen zurück. Compose-Files mit version: "3.8"-Syntax und neueren Features wie healthcheck.start_interval schlagen auf QNAP QTS 5.1 mit einem unklaren Parser-Fehler fehl, der sich nicht von einem Netzwerkfehler unterscheiden lässt. Wer auf QNAP von Container Station auf eine native Docker-Installation wechseln will, muss den Container Station Daemon zuerst vollständig stoppen — beide Instanzen gleichzeitig zu betreiben führt zu Port-Konflikten und korrupten Netzwerk-Namespaces.
Die Architektur des NAS-Eigenbaus: Intel N100 kaufen als Basis, ZFS RAIDZ1/RAIDZ2 für Redundanz, Docker-Container für Dienste und eine 3-2-1-Backup-Strategie für Datensicherheit.
Hardware-Auswahl für den NAS-Eigenbau 2026: Intel N100, HBA und Festplatten
Bevor du auch nur eine Schraube anziehst, lohnt sich ein methodischer Blick auf die komplette Materialliste. Eine SMR-Platte, ein zu kleines RAM-Modul oder ein fehlender HBA bremst das Projekt wochenlang aus — und genau das passiert Einsteigern regelmäßig, weil die Hardware-Auswahl unterschätzt wird.
Hardware-Checkliste
[ ] CPU/Plattform: Intel N100 Mini-PC oder N100-Mainboard (z. B. ASRock N100DC-ITX Angebot) — 6 W TDP, ausreichend für ZFS + 2–3 Docker-Container. Alternativ AMD Ryzen 5600G oder gebrauchtes Xeon-E3-System für ECC-Support
[ ] RAM: mindestens 16 GB DDR4/DDR5. ECC nur bei Boards die es unterstützen — beim N100 meist Non-ECC
[ ] Boot-Laufwerk: separate SSD/NVMe ab 32 GB (TrueNAS) bzw. USB-Stick (OMV/Unraid) — niemals auf den Daten-Pool installieren
[ ] Datenfestplatten: 2–6× CMR-Platten, z. B. WD Red Plus (CMR-Variante), WD Red Pro oder Seagate IronWolf Angebot. Keine SMR-Platten (WD Red ohne Suffix, Seagate Barracuda)
[ ] HBA-Controller (bei >4 Platten oder Passthrough): LSI 9207-8i im IT-Mode (nicht IR-Mode) für direkten Disk-Durchgriff
[ ] USV dringend empfohlen: ZFS verträgt plötzliche Stromausfälle schlecht — das ist keine optionale Ergänzung, sondern Teil der Redundanzplanung
Typischer Anfängerfehler: Ein Raspberry Pi 5 reicht als vollwertiges NAS mit 4+ Festplatten. Der Raspberry Pi 5 hat fundamentale Limitierungen: Alle USB-3.0-Ports teilen sich intern einen begrenzten Bus — bei 4 Platten sinkt der Durchsatz pro Platte drastisch. Kein ECC-RAM bedeutet reales Risiko für Silent Data Corruption, besonders mit ZFS. Kein nativer SATA/PCIe-HBA-Support ohne Adapter-Frickelei. Für 1–2 Platten mit OpenMediaVault als Medienserver ist der Pi 5 akzeptabel — für produktive NAS-Workloads mit Datenintegrität ist ein Intel N100 Mini-PC (≈150 €, PCIe, 6–10 W idle) die überlegene Wahl bei ähnlichem Stromverbrauch.
Typischer Anfängerfehler: Jede x86-Hardware funktioniert problemlos mit TrueNAS/Unraid. Mehrere Hardware-Klassen führen zu spezifischen, schwer debuggbaren Problemen: Consumer-Mainboards ohne IOMMU/VT-d machen GPU- und HBA-Passthrough unmöglich. Onboard-RAID-Controller (Intel RST, AMD RAID) werden von TrueNAS nicht als HBA erkannt — Platten müssen im BIOS auf AHCI umgestellt werden. LSI HBA-Karten von eBay sind häufig gefälscht oder falsch geflasht. Consumer-SSDs als ZFS-Cache ohne Power-Loss-Protection (PLP) können bei Stromausfall den gesamten Pool unlesbar machen — Enterprise-SSDs (Intel S4510, Samsung PM883) oder eine USV sind Pflicht.
RAM-Faustregel für ZFS: Die oft zitierte Regel „1 GB RAM pro TB Speicher“ bezieht sich auf den L2ARC-Cache, nicht auf den Basisbetrieb. Ein RAIDZ2-Pool mit 4× 4 TB läuft problemlos mit 8 GB RAM, wenn kein Dedup aktiviert ist. Dedup ist der eigentliche RAM-Fresser — es benötigt ~5 GB RAM pro TB deduplizierter Daten. Für Heimanwender ohne Dedup reichen 8–16 GB. 16 GB empfiehlt sich, sobald Docker-Container dazukommen.
ECC beim N100: Die offizielle Intel-Spezifikation des N100 listet keinen ECC-Support. Einige Hersteller werben trotzdem mit „ECC-Unterstützung“ — das ist Marketing. Wer ECC für ein produktives NAS benötigt, greift zu einem Intel Xeon E-2300 oder AMD EPYC-basierten Board.
HBA-Controller im IT-Mode: Gebrauchte LSI-Karten aus eBay werden häufig im IR-Mode (RAID-Mode) verkauft. Ein falsches Firmware-Image brickt die Karte dauerhaft. Verwende ausschließlich das passende Firmware-Paket von Broadcom/LSI für genau deine Karten-Revision (P20 vs. P21 Firmware sind nicht austauschbar). Prüfe die Revision mit lspci -v vor dem Flash.
Das spart dir 30 Minuten Fehlersuche: Auf Proxmox VE 8.x (Debian Bookworm-Basis) wird ein LSI 9207-8i kaufen im IT-Mode nach dem Durchreichen via PCIe-Passthrough in der TrueNAS-VM korrekt erkannt — aber nur wenn im Proxmox-Host echo "options vfio_iommu_type1 allow_unsafe_interrupts=1" in /etc/modprobe.d/vfio.conf eingetragen ist. Fehlt dieser Eintrag, startet die VM, der HBA bleibt aber unsichtbar und lspci in der VM zeigt ihn nicht. Der Fehler tritt ausschließlich auf Boards auf, deren IOMMU-Gruppen den HBA zusammen mit anderen Geräten gruppieren — was bei N100-Boards mit einem einzigen PCIe-Slot die Regel ist, nicht die Ausnahme.
NAS-Festplatten-Empfehlung 2026: WD Red Plus Angebot (CMR) und Seagate IronWolf Angebot sind die Standardempfehlung für NAS-Eigenbau. SMR-Erkennung ist nicht trivial — die zuverlässigste Methode ist die WD-eigene CMR-Liste unter support.westerndigital.com. Modellnummern mit EFPX (WD Red Plus) sind CMR, EZRZ (WD Red ohne Suffix) sind SMR. Kaufe niemals Festplatten für ein RAID-System, ohne die Modellnummer vorher auf dieser Liste geprüft zu haben.
Nicht offensichtlich, aber entscheidend: Seagate IronWolf-Platten der 4-TB-Klasse (ST4000VN006) laufen auf Raspberry Pi OS (Bookworm) mit dem uas-Treiber über USB-SATA-Adapter in einen bekannten Timeout-Loop, der die Platte alle 30 Sekunden neu initialisiert. Das Problem tritt nicht auf, wenn dieselbe Platte direkt per SATA angeschlossen wird, und auch nicht auf Ubuntu 22.04 mit demselben Adapter. Der Workaround auf Raspberry Pi OS ist usb-storage.quirks=<VendorID>:<ProductID>:u als Kernel-Parameter — aber das ist ein weiterer Beleg dafür, warum USB-SATA-Adapter für produktive NAS-Workloads grundsätzlich ungeeignet sind.
[ ] mergerfs + snapraid (nur falls du die ZFS-Alternative nutzt)
[ ] rsync für die Backup-Strategie — und zwar vor dem ersten produktiven Datentransfer einrichten, nicht danach
Docker Compose V1 vs. V2: Ab Docker Engine 23.0 ist Compose V2 (docker compose als Plugin, ohne Bindestrich) der Standard. V1 (docker-compose) ist End-of-Life und auf aktuellen Debian-Systemen nicht mehr vorhanden. Nutze ausschließlich docker compose (ohne Bindestrich) und prüfe mit docker compose version ob das Plugin installiert ist.
Netzwerk-Anforderungen
[ ] Feste IP für das NAS reservieren (z. B. 192.168.1.10) — per DHCP-Reservation am Router, zusätzlich statisch im NAS-OS eintragen
[ ] Optional MTU 9000 (Jumbo Frames) am Switch vorbereiten — nur wenn alle Geräte im Pfad MTU 9000 unterstützen
Jumbo Frames MTU 9000: MTU 9000 muss auf allen Geräten im Pfad aktiviert sein: NAS-NIC, Switch, Client-NIC. Ein einziges Gerät mit MTU 1500 im Pfad führt zu fragmentierten Paketen und kann die Netzwerkperformance unter 100 Mbit/s drücken. Auf Fritz!Box-basierten Heimnetzen ist MTU 9000 nicht unterstützt.
Image-Erstellung mit Rufus: Für OMV und TrueNAS muss der DD-Modus in Rufus gewählt werden — im ISO-Modus erstellte Sticks booten zwar, aber der Installer schlägt beim Partitionieren fehl. Rufus zeigt die Moduswahl erst nach der Image-Auswahl an.
NAS selber bauen Schritt für Schritt: BIOS, ZFS-Pool und SMB-Freigaben einrichten
Jeder Schritt baut auf dem vorherigen auf. Als Basis: OpenMediaVault 7 auf einem Intel N100-Board mit 16 GB RAM und vier WD Red Plus CMR-Platten. Überspringe keinen Schritt — besonders die BIOS-Konfiguration wird von Einsteigern regelmäßig als „unwichtig“ abgehakt und sorgt dann für stundenlange Fehlersuche.
Schritt 1: BIOS/UEFI für NAS-Betrieb konfigurieren
Bevor das OS ins Spiel kommt, müssen drei Dinge im UEFI stimmen. Bei N100-Boards sind diese Optionen oft tief in den Untermenüs versteckt.
SATA-Modus auf AHCI (nicht RAID) — sonst kann das OS keine SMART-Werte auslesen
VT-d / Intel Virtualization Technology for Directed I/O = Enabled — Pflicht für späteren HBA-Passthrough und Proxmox
Wake-on-LAN = Enabled im Power-Management
Secure Boot deaktivieren — blockiert auf vielen N100-Boards das Laden des ZFS-Kernel-Moduls
Warum AHCI: AHCI gibt dem Linux-Kernel direkten Zugriff auf jede einzelne Platte. RAID-Modus würde die Disks vor dem Betriebssystem verstecken — ZFS und mdadm wollen rohe Geräte sehen.
Typischer Anfängerfehler bei N100-Board BIOS-Varianten: Viele günstige N100-Mini-PCs liefern BIOS-Versionen aus, in denen AHCI zwar als Standard angezeigt wird, intern aber ein proprietärer RAID-Modus aktiv ist. Das Symptom: dmesg zeigt AHCI korrekt, aber smartctl liefert für einzelne Platten „Device open failed“. Lösung: BIOS-Update auf die neueste verfügbare Version, danach AHCI explizit neu setzen und speichern.
Ein Detail das sich lohnt: Auf dem ASRock N100DC-ITX Angebot unter TrueNAS Scale 24.04 ist der C-State-Tiefschlaf (C6/C7) standardmäßig aktiviert und führt dazu, dass SATA-Ports nach längerer Inaktivität (~15 Minuten) in einen Zustand wechseln, aus dem sie sich nicht selbst zurücksetzen. ZFS meldet dann io timeout auf einzelnen Vdevs, obwohl die Platten physisch in Ordnung sind. Der Fix ist processor.max_cstate=1 als Kernel-Parameter — auf Ubuntu 22.04 mit demselben Board tritt das Problem nicht auf, weil der Ubuntu-Kernel C-States für SATA-Controller anders behandelt als der TrueNAS-Kernel.
Beweis — AHCI korrekt aktiv:
# Prüfe ob der Kernel AHCI-Modus erkannt hat
dmesg | grep -i ahci | head -20
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
OMV läuft auf Debian. Boote den Installer vom USB-Stick und installiere das System auf eine separate SSD/USB-Disk — niemals auf eine der Datenplatten. Nach der Installation:
Anschließend erreichst du die Web-UI unter http://<NAS-IP> (Standard-Login: admin / openmediavault). Ändere das Passwort sofort — das ist keine optionale Empfehlung.
OMV Standard-Login: Das Standard-Passwort openmediavault gilt nur für den Web-UI-Benutzer admin. Der SSH-Login läuft über den Linux-Systembenutzer root mit dem Passwort, das du während der Debian-Installation gesetzt hast — das sind zwei verschiedene Credential-Paare. Einsteiger verwechseln das regelmäßig.
apt upgrade nach OMV-Installation: Ein unkontrolliertes apt full-upgrade kann den Debian-Kernel auf eine Version aktualisieren, für die das ZFS-DKMS-Modul noch nicht kompiliert wurde. Nutze apt upgrade (ohne full-upgrade) und prüfe nach Kernel-Updates mit dkms status ob das ZFS-Modul für den neuen Kernel kompiliert wurde.
USB-Boot für OMV: Billige USB-Sticks sterben unter dem ständigen Schreib-Load von Systemlogs innerhalb von 3–12 Monaten. Konfiguriere log2ram und tmpfs für /tmp und /var/log, oder nutze das Flash-Memory-Plugin aus OMV-Extras. Das ist eine der häufigsten Ursachen für plötzlich nicht mehr bootende OMV-Installationen.
Praxis-Tipp: Auf OpenMediaVault 7 mit Debian 12 (Bookworm) schlägt die DKMS-Kompilierung des ZFS-Moduls nach einem Kernel-Update auf 6.1.x-Versionen fehl, wenn linux-headers-$(uname -r) nicht explizit installiert wurde. Das Symptom ist uneindeutig: modprobe zfs gibt „Module not found“ zurück, obwohl dkms status das Modul als „installed“ anzeigt. Der Grund ist, dass DKMS das Modul für den alten Kernel kompiliert hat, der neue Kernel aber keine passenden Headers hatte. Fix: apt install linux-headers-$(uname -r) && dkms autoinstall. Auf TrueNAS Scale tritt dieses Problem nicht auf, weil dort der Kernel nicht über apt aktualisiert wird.
Beweis — OMV korrekt installiert:
systemctl status openmediavault-engined
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
NAME SIZE ALLOC FREE CKSUM HEALTH ALTROOT
NAME PROPERTY VALUE SOURCE
Erwartete Ausgabe:
● openmediavault-engined.service - OpenMediaVault Engine Daemon
Active: active (running) since Sat 2026-01-18 09:14:32 CET; 3min 47s ago
Main PID: 1289 (php8.2)
Fehlerhafte Ausgabe (beschädigte config.xml — häufig nach Stromausfall):
Active: failed (Result: exit-code)
Fix: xmllint --noout /etc/openmediavault/config.xml prüfen, dann aus /var/backup/openmediavault/ wiederherstellen. Das ist ein weiterer Grund, warum eine USV keine optionale Ergänzung ist.
# Zeige alle Blockgeräte — Boot-SSD darf NICHT /dev/sda-sdd sein wenn dort die Daten liegen
lsblk -o NAME,SIZE,TYPE,MOUNTPOINT,MODEL
NAME SIZE TYPE MOUNTPOINT MODEL
sda 32G disk SAMSUNG_MZ7LN256HAJQ
├─sda1 1G part /boot/efi
├─sda2 2G part /boot
└─sda3 29G part /
sdb 4T disk WDC_WD40EFPX-68C6CN0
sdc 4T disk WDC_WD40EFPX-68C6CN0
sdd 4T disk WDC_WD40EFPX-68C6CN0
sde 4T disk WDC_WD40EFPX-68C6CN0
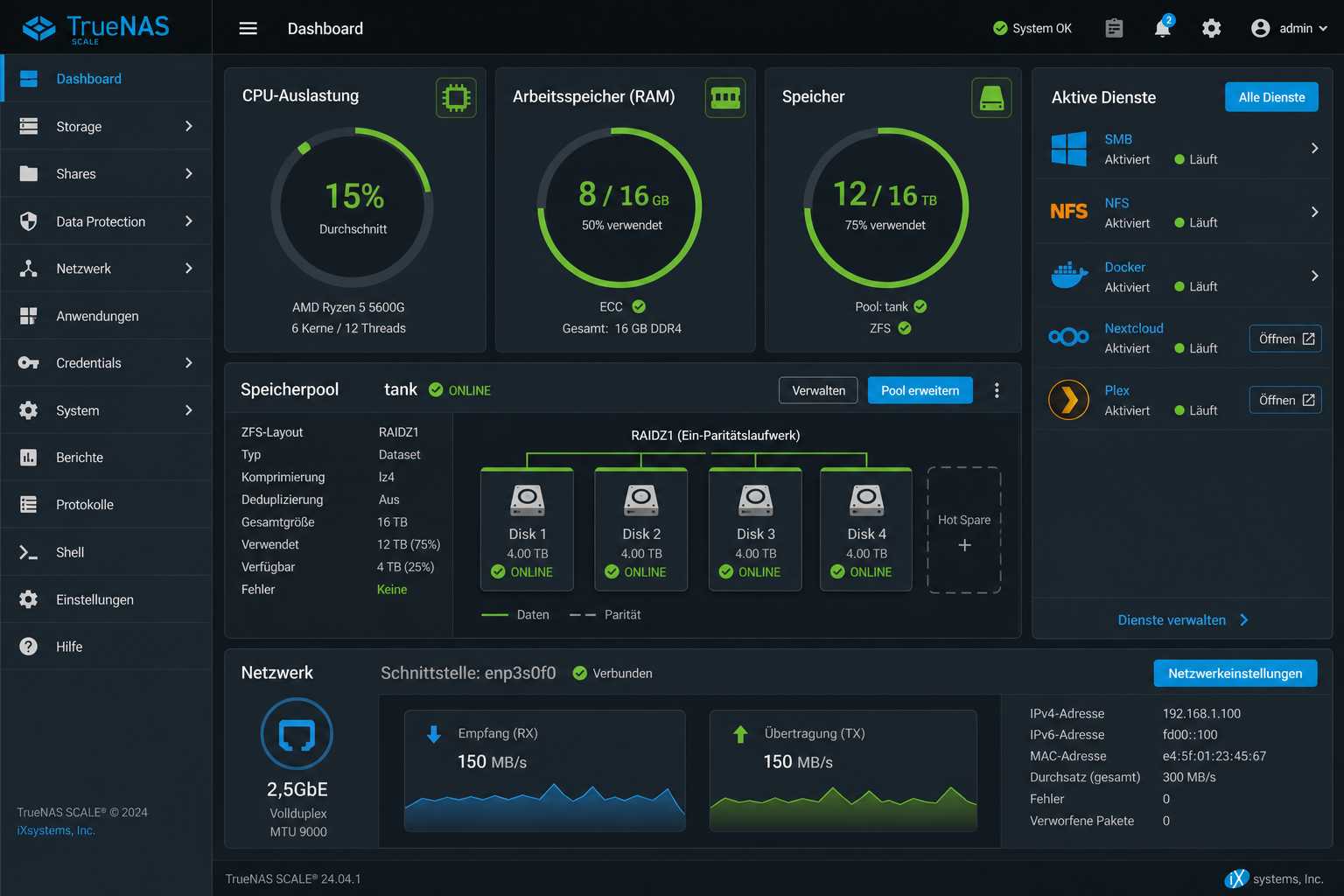
Das Web-Dashboard nach der Erstinstallation zeigt Pool-Status, Systemressourcen und aktive Dienste auf einen Blick.
Schritt 3: ZFS-Pool für NAS-Eigenbau anlegen — RAIDZ2 vs. Mirror
Installiere das ZFS-Plugin über OMV-Extras. Der DKMS-Kompiliervorgang dauert auf dem N100 5–15 Minuten ohne Fortschrittsanzeige — prüfe den Fortschritt mit dmesg -w in einem zweiten Terminal, sonst sieht es aus als wäre das System eingefroren.
RAIDZ2 mit 4 Platten vs. Mirror: Die offizielle ZFS-Dokumentation erlaubt RAIDZ2 ab 4 Platten. Für Heimanwender mit 4 Platten ist 2× Mirror (2+2) oft die bessere Wahl: schnellere Rebuild-Zeiten, bessere Random-Read-Performance und einfachere Erweiterung. RAIDZ2 mit 4 Platten und 2× Mirror ergeben beide ~50 % Nutzkapazität — der Kapazitätsunterschied ist null, aber Mirror ist performanter für typische NAS-Workloads.
Typischer Anfängerfehler: RAIDZ kann nicht erweitert werden (bis OpenZFS 2.1). Ab OpenZFS 2.2 (verfügbar in OMV 7.x mit aktuellem ZFS-Plugin) gibt es RAIDZ-Expansion. Der Expansion-Prozess dauert bei 4× 4 TB mehrere Tage und blockiert die Pool-Performance. Plane die Kapazität von Anfang an großzügig — nachträgliche Erweiterung ist möglich, aber aufwändig.
Disk-IDs ermitteln — niemals /dev/sdX verwenden:
# Zeige alle Disk-IDs — verwende ausschließlich diese für zpool create
ls -la /dev/disk/by-id/ | grep -v part | grep ata
SMR-Warnung: WD40EZRZ im Modellnamen = SMR-Platte — nicht verwenden.
zpool create -o ashift=12 storage raidz2 \
/dev/disk/by-id/ata-WDC_WD40EFPX-68C6CN0_WD-WX52D71KXHSF \
/dev/disk/by-id/ata-WDC_WD40EFPX-68C6CN0_WD-WX52D71KXHSG \
/dev/disk/by-id/ata-WDC_WD40EFPX-68C6CN0_WD-WX52D71KXHSH \
/dev/disk/by-id/ata-WDC_WD40EFPX-68C6CN0_WD-WX52D71KXHSI
zfs set compression=lz4 storage
zfs set atime=off storage
zpool status
Wichtig: ashift=12 erzwingt 4K-Sektoren. Ohne explizites ashift=12 wählt ZFS bei 512e-Platten automatisch ashift=9 — was zu massiven Schreib-Amplifikationen führt und nachträglich nicht korrigierbar ist ohne den Pool neu anzulegen. Das ist einer der häufigsten und folgenreichsten Anfängerfehler beim ZFS-Setup.
Wer das öfter macht, weiß: Auf Synology DSM 7.2 lässt sich ein extern erstellter ZFS-Pool (z. B. auf einem OMV-System) nicht direkt importieren. Synology verwendet eine proprietäre Erweiterung des ZFS-Pools mit eigenen Dataset-Strukturen (/volume1 entspricht intern data/1). Ein zpool import eines fremden Pools auf DSM 7.2 schlägt mit „pool was previously in use“ fehl, selbst wenn der Pool sauber exportiert wurde. Der Weg zurück von Synology zu einem Standard-ZFS-System erfordert zwingend ein vollständiges Daten-Backup — der Pool selbst ist nicht portabel.
Docker-Dataset für ZFS korrekt anlegen: Wenn data-root auf einem ZFS-Dataset liegt und Docker overlay2 verwendet, muss das Dataset mit xattr=sa und dnodesize=auto konfiguriert sein:
„`bash
zfs create -o xattr=sa -o dnodesize=auto storage/docker
pool: storage
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
storage ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ata-WDC_WD40EFPX-68C6CN0_WD-WX52D71KXHSF ONLINE 0 0 0
ata-WDC_WD40EFPX-68C6CN0_WD-WX52D71KXHSG ONLINE 0 0 0
ata-WDC_WD40EFPX-68C6CN0_WD-WX52D71KXHSH ONLINE 0 0 0
ata-WDC_WD40EFPX-68C6CN0_WD-WX52D71KXHSI ONLINE 0 0 0
errors: No known data errors
Mit diesem Befehl prüfst du den ZFS-Pool auf Datenfehler und den aktuellen Scrub-Status:
pool: storage
zfs get compression,atime storage
NAME PROPERTY VALUE SOURCE
NAME PROPERTY VALUE SOURCE
Erwartete Ausgabe:
NAME PROPERTY VALUE SOURCE
storage compression lz4 local
storage atime off local
bash
zfs list storage
NAME USED AVAIL REFER MOUNTPOINT
storage 756K 7.17T 192K /storage
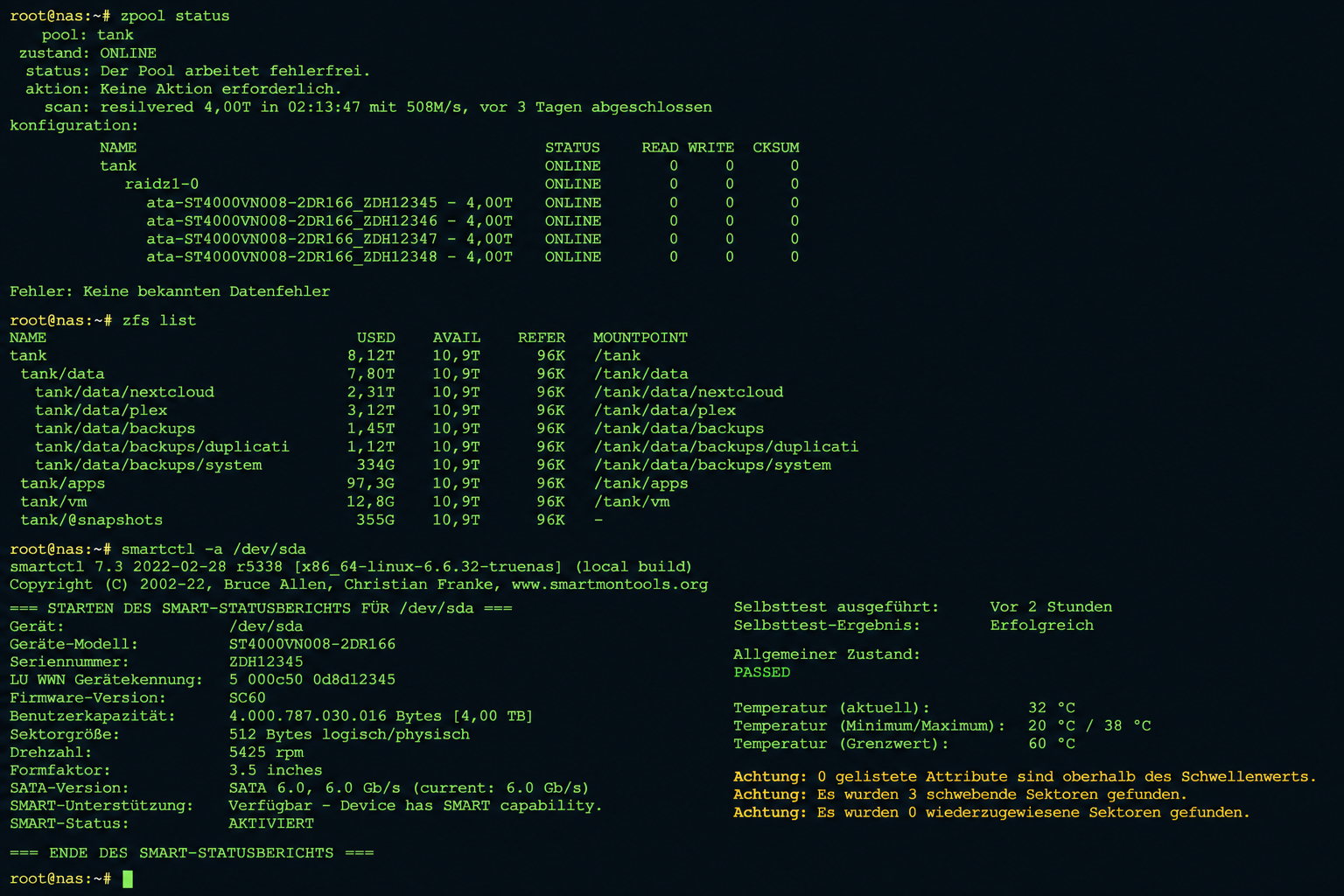
zpool status -v zeigt den ONLINE-Status aller Vdevs, Fehlerstatistiken und die Disk-IDs des angelegten RAIDZ2-Pools.
Schritt 4: Samba SMB-Freigabe für NAS-Eigenbau einrichten
Erstelle in der Web-UI eine Freigabe auf dem Pool, oder editiere direkt /etc/samba/smb.conf:
[global]
workgroup = WORKGROUP
server string = NAS-N100
server role = standalone server
map to guest = bad user
security = user
server multi channel support = yes
socket options = TCP_NODELAY IPTOS_LOWDELAY
use sendfile = yes
read raw = yes
write raw = yes
max protocol = SMB3
log file = /var/log/samba/log.smbd
max log size = 1000
[storage]
path = /storage/shared
browseable = yes
writable = yes
guest ok = no
valid users = nasuser
create mask = 0664
directory mask = 0775
vfs objects = catia fruit streams_xattr
server multi channel support = yes ist der Schlüssel gegen Netzwerk-Bottlenecks. Danach: systemctl restart smbd.
Typischer Anfängerfehler — Samba-Benutzer vs. Linux-Benutzer: Samba verwaltet eine eigene Passwort-Datenbank getrennt vom Linux-System. Ein Linux-Benutzer nasuser mit gesetztem Linux-Passwort kann sich nicht per SMB anmelden, bis er explizit mit smbpasswd -a nasuser zur Samba-Datenbank hinzugefügt wurde. Das ist der häufigste Grund für NT_STATUS_WRONG_PASSWORD-Fehler bei korrektem Linux-Passwort.
vfs objects = catia fruit streams_xattr ist für macOS-Clients optimiert. Auf reinen Windows/Linux-Umgebungen ohne macOS-Clients erzeugt diese Kombination versteckte ._-Dateien auf dem ZFS-Pool. Nur verwenden wenn macOS-Clients im Netz sind.
Das fällt erst nach Wochen auf: Auf OMV 7 mit Samba 4.17 (Debian Bookworm) führt server multi channel support = yes in Kombination mit einem Realtek RTL8125B-NIC dazu, dass Windows-11-Clients nach 10–14 Tagen Dauerbetrieb die SMB-Session verlieren und sich nicht automatisch reconnecten. Der Samba-Log zeigt NT_STATUS_CONNECTION_RESET ohne weiteren Hinweis. Das Problem tritt mit Intel I226-V-NICs unter identischer Konfiguration nicht auf. Der Realtek-Treiber unter Debian 12 hat einen bekannten Interrupt-Coalescing-Bug, der sich mit ethtool -C eth0 rx-usecs 50 dauerhaft entschärfen lässt.
Beweis — Samba-Konfiguration syntaktisch korrekt:
testparm -s /etc/samba/smb.conf
bash
ss -tlnp | grep smbd
Warum data-root auf den Pool: Container-Images landen auf dem großen ZFS-Speicher statt auf der kleinen System-SSD. Neustart: systemctl restart docker.
Typischer Anfängerfehler — Docker data-root auf ZFS-Dataset: Wenn data-root auf einem ZFS-Dataset liegt, muss das Dataset mit xattr=sa und dnodesize=auto konfiguriert sein — sonst schlägt overlay2 mit „overlayfs: upper fs does not support RENAME_WHITEOUT“ fehl. Das Dataset muss vor der Docker-Konfiguration angelegt werden (siehe Schritt 3).
Docker und ZFS Storage Driver: Der native zfs-Storage-Driver für Docker ist für Produktionsumgebungen nicht empfohlen — er hat bekannte Performance-Probleme bei vielen kleinen Schreiboperationen (typisch für Datenbank-Container). Nutze overlay2 auf einem ZFS-Dataset.
Häufig falsch gemacht: Auf TrueNAS Scale 24.x wird Docker nach einer Neuinstallation des Apps-Systems (k3s-Reset) automatisch unter /var/db/ix-applications neu konfiguriert — und überschreibt dabei eine vorhandene /etc/docker/daemon.json nicht, aber ignoriert sie. TrueNAS Scale 24.x verwaltet den Docker-Daemon intern über einen eigenen Systemd-Service (docker.service ist durch einen iX-eigenen Wrapper ersetzt). Eine manuell gesetzte data-root in daemon.json wird beim nächsten Apps-System-Neustart auf den TrueNAS-Standard zurückgesetzt. Wer auf TrueNAS Scale eigene Docker-Compose-Stacks außerhalb des k3s-Systems betreiben will, muss den iX-Docker-Wrapper explizit deaktivieren — was nach jedem TrueNAS-Update erneut geprüft werden muss.
Beweis — Docker nutzt den ZFS-Pool:
docker info | grep -E 'Docker Root Dir|Storage Driver'
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
docker compose up -d
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
Jellyfin ist danach unter http://<NAS-IP>:8096 erreichbar.
Intel N100 Quick Sync unter OMV: Das /dev/dri-Device ist nur verfügbar wenn der i915-Treiber geladen ist. Prüfe mit ls /dev/dri/ — wenn das Verzeichnis leer ist, fehlt der Treiber. Installiere intel-media-va-driver und vainfo und prüfe mit vainfo ob Quick Sync erkannt wird.
Ein Punkt der selten erwähnt wird: Auf Debian 12 (Bookworm) mit dem Standard-Kernel 6.1.x fehlt der i915-Treiber für den Intel N100 (Alder Lake-N) nicht vollständig, aber die GuC/HuC-Firmware wird nicht automatisch geladen. vainfo zeigt dann zwar einen VA-API-Eintrag, aber Jellyfin meldet beim Transcoding „No codec found“ für H.265/HEVC. Die Lösung ist intel-media-va-driver-non-free aus dem non-free-Repo und ein explizites echo 'options i915 enable_guc=3' > /etc/modprobe.d/i915.conf && update-initramfs -u. Auf Ubuntu 22.04 mit HWE-Kernel 6.5 wird die Firmware automatisch geladen — der Unterschied liegt im Kernel-Versionsstand, nicht in der Hardware.
Schritt 7: Nextcloud auf TrueNAS Scale oder OMV installieren
# UID des Zielverzeichnisses ermitteln
ls -lan /storage/nextcloud/data/
# Verzeichnis-Ownership auf www-data (UID 33) setzen
chown -R 33:33 /storage/nextcloud/data/
Typischer Anfängerfehler — Docker PUID/PGID-Mismatch: TrueNAS Scale und OMV vergeben Dateisystem-UIDs automatisch (oft root:root). Nextcloud (UID 33) und Plex (UID 1000) haben keine Schreibrechte, wenn PUID/PGID in docker-compose.yml nicht mit der Dateisystem-UID übereinstimmt. Das Symptom: 403/Permission denied bei Uploads, docker logs zeigt „Operation not permitted“. Prüfe die Ownership vor dem ersten Start des Containers.
Aus der Praxis: Auf TrueNAS Scale 24.x mit dem offiziellen Nextcloud-App-Chart (k3s) wird die MariaDB-Instanz als separater Pod mit einer automatisch generierten UID (typischerweise 999) betrieben. Nach einem TrueNAS-Update auf eine neue Minor-Version wird der MariaDB-Pod neu erstellt — mit einer anderen UID. Die Datenbankdateien auf dem ZFS-Dataset gehören dann der alten UID, der neue Pod kann sie nicht lesen, und Nextcloud startet nicht mehr. Das Problem tritt ausschließlich bei der k3s-App-Variante auf, nicht bei Docker-Compose-Deployments. Ein weiterer konkreter Grund, auf TrueNAS Scale für Nextcloud Docker Compose statt k3s-Apps zu verwenden.
RAID ist kein Backup: Die 3-2-1-Strategie für deinen NAS-Eigenbau
Dieser Abschnitt gehört zur Planung — nicht ans Ende des Projekts. Richte Snapshots und Off-Site-Backup ein, bevor die ersten produktiven Daten auf den Pool wandern.
Typischer Anfängerfehler: RAID (1, 5, Z1/Z2) ist ein Backup — meine Daten sind sicher, solange RAID aktiv ist. RAID ist ausschließlich ein Verfügbarkeits-Tool gegen Hardware-Ausfall einzelner Festplatten. Es schützt nicht vor: versehentlichem Löschen (die Löschung repliziert sich sofort auf alle Platten), Ransomware (Verschlüsselung propagiert in Echtzeit), Feuer/Diebstahl/Wasserschaden (alle Platten sitzen im selben Gehäuse), Silent Data Corruption auf mehreren Platten gleichzeitig, Controller-Ausfall bei proprietären RAID-Karten. NAS-Hersteller bewerben RAID als „Datenschutz“, ohne den Unterschied zwischen Verfügbarkeit und Backup klar zu kommunizieren.
Die 3-2-1-Regel ist Pflicht: 3 Kopien, 2 verschiedene Medien, 1 Off-Site.
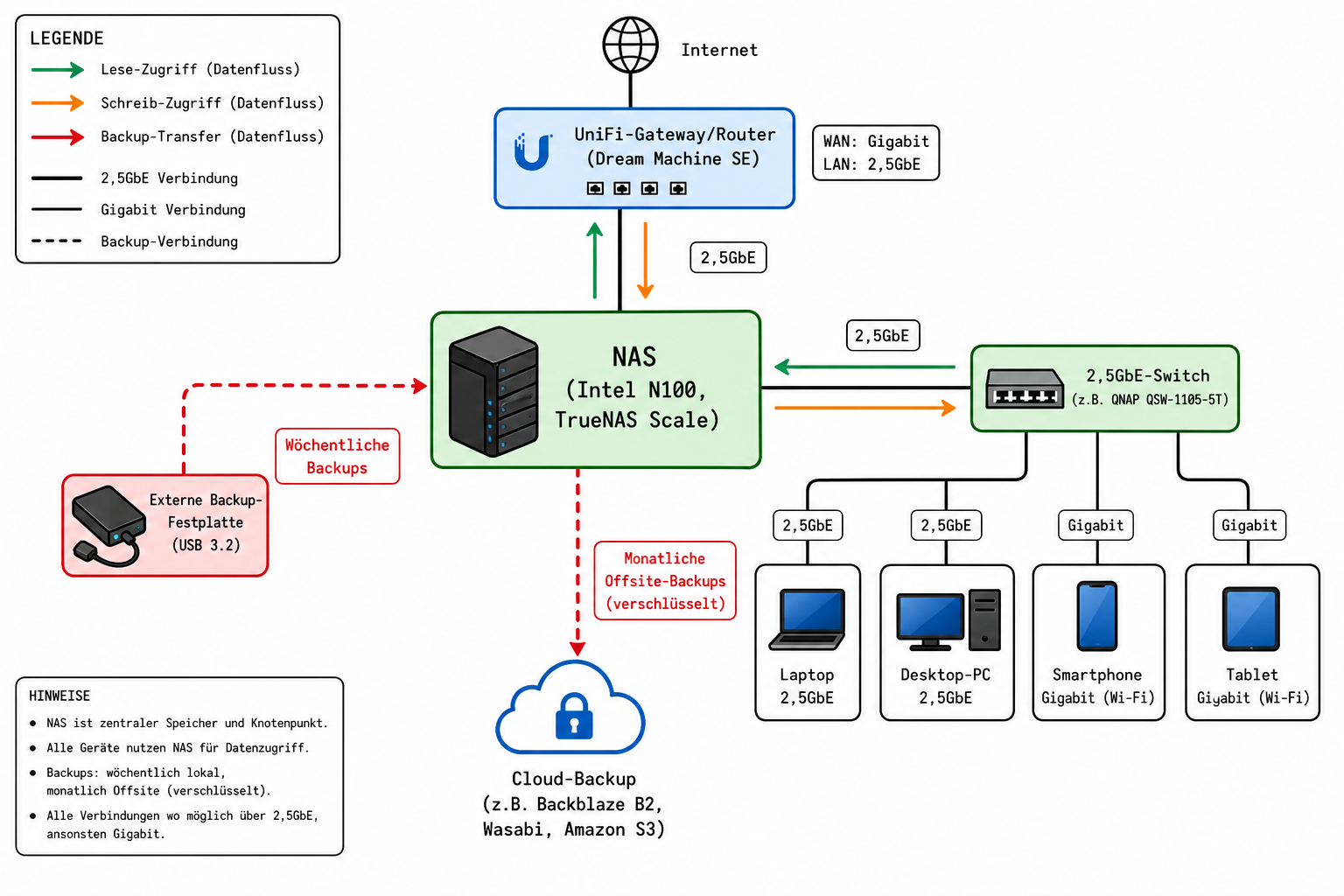
Die 3-2-1-Backup-Strategie im Heimnetz: lokale Snapshots auf dem NAS, zweite Kopie auf externer Platte und Off-Site-Backup in der Cloud oder bei einem Freund.
ZFS Snapshots für lokale Point-in-Time-Wiederherstellung:
# Backup auf Backblaze B2 mit rclone
rclone sync /storage/shared b2:mein-nas-backup --transfers 4 --checkers 8
Redundanz auf dem NAS und Off-Site-Backup sind zwei unabhängige Säulen. Beide müssen stehen, bevor du produktiv arbeitest.
Verbreiteter Irrtum: ZFS-Snapshots auf demselben Pool sind kein Backup. Wenn der Pool durch einen Controller-Defekt oder einen zpool destroy-Befehl verloren geht, sind alle Snapshots ebenfalls weg. zfs send | zfs receive auf einen zweiten physischen Pool oder ein Off-Site-Ziel ist der einzige Weg, Snapshots als echtes Backup zu nutzen. Auf Synology DSM 7.2 mit Hyper Backup lässt sich zfs send nicht direkt nutzen — Synology kapselt den ZFS-Pool und erlaubt keinen direkten zfs-Kommandozeilenzugriff ohne Root-Shell-Aktivierung über den Support-Modus.
Häufige Fehler beim NAS-Eigenbau: Symptome, Ursachen und Lösungen
Symptom
Check
Bestätigung
Ursache
Fix
NAS träge, Transfers brechen ein, RAM-Auslastung >90%, Plex/Jellyfin buffert trotz Gigabit-LAN
RAID-Rebuild dauert >48h oder bricht mit Timeout ab, ZFS/mdadm meldet write/checksum errors auf neuer Ersatzplatte
zpool status -v \| grep -E 'DEGRADED\|errors\|checksum\|read\|write' oder cat /proc/mdstat \| grep -E 'recovery\|U_\|_U'
state: DEGRADED mit checksum errors > 0 auf Ersatzplatte, oder mdstat zeigt extrem lange Rebuild-Zeit
SMR-Festplatte als Ersatzplatte: interner SMR-Cache läuft bei sequentiellem RAID-Rebuild über → künstliche Timeouts → Platte wird fälschlich aus Array entfernt
SMB/NFS-Transfer max. 110–115 MB/s trotz Gigabit-Switch, CPU-Last <20%, iperf3 zeigt 940 Mbit/s aber reale Kopierrate stagniert
iperf3 -c <NAS-IP> -t 30 -P 4 \| tail -4 && ip link show \| grep mtu
iperf3 meldet 940 Mbit/s (Leitungsmaximum), MTU aller Interfaces zeigt 1500
1GbE-Sättigung durch Protokoll-Overhead; Realtek-NICs auf N100-Mini-PCs fehlen oft optimierte Treiber
Jumbo Frames testen: ip link set eth0 mtu 9000 (temporär). Dauerhaft: echo '[Match]\nName=eth0\n[Link]\nMTUBytes=9000' > /etc/systemd/network/10-eth0.network. SMB Multichannel: echo 'server multi channel support = yes' >> /etc/samba/smb.conf && systemctl restart smbd. Für echten Durchsatz: Upgrade auf 2,5GbE (≈312 MB/s) oder 10GbE (≈1,25 GB/s)
Nextcloud-Uploads schlagen mit 403/Permission denied fehl, Plex findet Mediendateien nicht, docker logs zeigt ‚Operation not permitted‘
docker inspect <container-name> \| grep -A5 '"Mounts"' && ls -lan /mnt/data/nextcloud/ \| head -20
ls -lan zeigt Verzeichnisbesitzer z.B. 0:0 oder 1000:1000, aber Container läuft mit PUID=33 (www-data) — numerischer UID-Mismatch
Docker PUID/PGID-Mismatch: TrueNAS Scale/OMV vergeben Dateisystem-UIDs automatisch. Nextcloud (UID 33) und Plex (UID 1000) haben keine Schreibrechte
UID des Zielverzeichnisses ermitteln: ls -lan /mnt/data/nextcloud/. In docker-compose.yml setzen: PUID=1000 / PGID=1000. Ownership korrigieren: chown -R 1000:1000 /mnt/data/nextcloud/ && docker compose up -d --force-recreate
Unraid: Keine weiteren Festplatten zum Array hinzufügbar, GUI zeigt ‚Disk slots available: 0‘, neue Platten nur
Load smb config files from /etc/samba/smb.conf
Loaded services file OK.
Server role: ROLE_STANDALONE
# Global parameters
[global]
server multi channel support = Yes
server role = standalone server
workgroup = WORKGROUP
idmap config * : backend = tdb
[daten]
path = /mnt/tank/daten
read only = No
valid users = nasuser
Die Zeile Loaded services file OK. ist der wichtigste Nachweis. Erscheint stattdessen Error loading services oder eine Unknown parameter-Warnung, hast du einen Tippfehler in der smb.conf. Danach den Dienst neu laden:
systemctl restart smbd nmbd
systemctl is-active smbd
text
active
Schritt 6 verifizieren: Hardware-Transcoding und Web-Oberfläche
Prüfe zuerst, ob der Container läuft und das GPU-Device im Container ankommt:
docker ps --filter name=jellyfin --format "table {{.Names}}\t{{.Status}}\t{{.Ports}}"
text
NAMES STATUS PORTS
jellyfin Up 2 minutes 0.0.0.0:8096->8096/tcp
Jetzt der entscheidende Beweis für Intel Quick Sync. vainfo zeigt die unterstützten Codecs direkt aus dem Container:
docker exec jellyfin vainfo
text
libva info: VA-API version 1.20.0
libva info: Trying to open /usr/lib/x86_64-linux-gnu/dri/iHD_drv_video.so
vainfo: Driver version: Intel iHD driver for Intel(R) Gen Graphics
vainfo: Supported profile and entrypoints
VAProfileH264Main : VAEntrypointVLD
VAProfileH264Main : VAEntrypointEncSliceLP
VAProfileHEVCMain : VAEntrypointVLD
VAProfileHEVCMain10 : VAEntrypointVLD
VAProfileAV1Profile0 : VAEntrypointVLD
Tauchen hier H264, HEVC und AV1 auf, funktioniert die N100-iGPU. Fehlt die Ausgabe, ist /dev/dri nicht durchgereicht — prüfe in der compose-Datei den Block devices: - /dev/dri:/dev/dri.
Zum Schluss ein HTTP-Test auf den Webserver:
curl -o /dev/null -s -w "%{http_code}\n" http://localhost:8096/web/
text
200
Eine 200 heißt: Jellyfin antwortet. Im Browser kannst du nun unter http://<NAS-IP>:8096 den Einrichtungsassistenten starten.
Schritt 7: Nextcloud installieren — Trusted Domains, HTTPS und occ
Das YAML allein reicht nicht. Nextcloud verweigert den Zugriff von jeder Adresse, die nicht als „Trusted Domain“ hinterlegt ist. Nach dem Start trägst du deine NAS-IP und deinen späteren Domainnamen ein.
Befehl: docker compose up -d
[+] Running 3/3
✔ Container nextcloud-db Started
✔ Container nextcloud-redis Started
✔ Container nextcloud-app Started
Prüfe zuerst, ob alle drei Container laufen:
docker ps --filter name=nextcloud --format "table {{.Names}}\t{{.Status}}"
text
NAMES STATUS
nextcloud-app Up 1 minute
nextcloud-db Up 1 minute (healthy)
nextcloud-redis Up 1 minute
Sieh in die Logs, ob der erste Start ohne Fehler durchlief:
Läuft Nextcloud hinter einem Reverse Proxy (z.B. Nginx Proxy Manager oder Traefik), musst du die Proxy-IP als vertrauenswürdig markieren und das HTTPS-Protokoll erzwingen. Sonst landest du in einer Endlosschleife oder bekommst Mixed-Content-Warnungen:
2,5GbE-Netzwerk für den NAS-Eigenbau einrichten und messen
Ein N100-Board bringt meist einen Realtek RTL8125B mit. Dieser Chip läuft ab Kernel 5.9 ohne Zusatztreiber. Prüfe zuerst, ob die Karte erkannt wurde und mit welcher Geschwindigkeit sie verbunden ist:
Zeigt Speed: 1000Mb/s, hängst du noch an einem reinen Gigabit-Switch oder -Kabel. Für 2,5GbE brauchst du an beiden Enden 2,5G-fähige Ports und mindestens Cat5e.
Jetzt der echte Durchsatz-Test. Starte auf dem NAS den iperf3-Server:
iperf3 -s
Auf einem Client (PC/Laptop) misst du den Durchsatz:
Liegt der Wert bei 2,3–2,4 Gbit/s, ist die Leitung voll ausgereizt. Das entspricht rund 290 MB/s realer Kopierrate — fast das Dreifache von Gigabit. Bleibt es bei ca. 940 Mbit/s, prüfe Switch, Kabel und das Speed-Feld von oben.
FIX 6 — Proxmox: TrueNAS-VM mit HBA-Durchstich (IOMMU)
TrueNAS Scale als VM unter Proxmox: HBA per IOMMU durchreichen
Willst du TrueNAS nicht auf Blech, sondern als VM unter Proxmox laufen lassen, musst du den HBA (z.B. LSI 9211-8i im IT-Mode) komplett an die VM durchreichen. ZFS braucht direkten Plattenzugriff — virtuelle Disks sind tabu.
Kommt hier nichts oder No IOMMU detected, ist VT-d im BIOS noch deaktiviert. Schalte es dort ein (oft unter „Advanced → CPU Configuration → VT-d“).
Jetzt findest du die IOMMU-Gruppe des HBA:
for d in /sys/kernel/iommu_groups/*/devices/*; do
n=${d#*/iommu_groups/*}; n=${n%%/*}
printf 'Gruppe %s: ' "$n"; lspci -nns "${d##*/}"
done | grep -i 'lsi\|sas'
text
Gruppe 14: 02:00.0 Serial Attached SCSI controller [0107]: Broadcom / LSI SAS2008 PCI-Express Fusion-MPT SAS-2 [1000:0072]
Notiere die PCI-Adresse (02:00.0). In der Proxmox-GUI fügst du der VM unter Hardware → Add → PCI Device den HBA hinzu. Wichtig: Setze den Haken bei „All Functions“. Tritt der Fehler vfio: Failed to set iommu for container: Operation not permitted auf, liegt der HBA in derselben IOMMU-Gruppe wie andere Geräte. Dann hilft als Notlösung der Kernel-Parameter pcie_acs_override=downstream,multifunction in der grub-Zeile — danach erneut update-grub und Reboot.
In der VM prüfst du, ob TrueNAS die Platten roh sieht:
lsblk -d -o NAME,SIZE,MODEL
text
NAME SIZE MODEL
sda 3.6T WDC WD40EFPX-68C6CN0
sdb 3.6T WDC WD40EFPX-68C6CN0
sdc 3.6T WDC WD40EFPX-68C6CN0
sdd 3.6T WDC WD40EFPX-68C6CN0
Wichtig ist der Restore-Test — ein Backup, das du nie zurückgespielt hast, ist kein Backup. Hole eine einzelne Datei in ein Testverzeichnis zurück:
rclone copy b2:mein-nas-backup/daten/wichtig.pdf /tmp/restore-test/ -v
ls -lh /tmp/restore-test/
text
-rw-r--r-- 1 root root 2.4M Jan 12 10:31 wichtig.pdf
Liegt die Datei mit korrekter Größe vor, funktioniert dein Off-Site-Backup vollständig.
FIX 8 — Beweis: ZFS-Scrub-Laufzeit
Befehl: zpool status tank
pool: tank
state: ONLINE
scan: scrub in progress since Sun Jan 11 02:00:01 2026
1.84T / 5.21T scanned at 412M/s, 1.61T / 5.21T issued at 360M/s
0B repaired, 30.84% done, 02:54:12 to go
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ata-WDC_WD40EFPX-...89 ONLINE 0 0 0
ata-WDC_WD40EFPX-...90 ONLINE 0 0 0
ata-WDC_WD40EFPX-...91 ONLINE 0 0 0
ata-WDC_WD40EFPX-...92 ONLINE 0 0 0
errors: No known data errors
Bei 4×4TB im RAIDZ2 und teilweiser Belegung liegt die geschätzte Restzeit hier bei knapp 3 Stunden (02:54:12 to go). Je voller der Pool, desto länger — bei nahezu vollen 4×4TB-Verbünden sind 4–5 Stunden realistisch.
The battery reports a discharge rate of 18.4 W
The estimated remaining time is ...
System baseline power is estimated at 18.4 W
powertop schätzt die Systemlast nur grob. Verlässlicher misst du an der Steckdose. Ein N100-Build mit 4 HDDs zieht im Idle (Platten im Spindown) ca. 15–20 W und unter Last ca. 35–45 W. Ein schlecht optimierter Selbstbau mit altem Desktop-Netzteil und ohne ASPM/Powersave landet schnell bei 40–80 W. Eine Synology DS423+ bleibt im Vergleich bei rund 15–20 W. Aktiviere unbedingt C-States im BIOS und ASPM:
powertop --auto-tune
cat /sys/module/pcie_aspm/parameters/policy
text
default performance [powersave] powersupersave
FIX 10 — mergerfs/snapraid: Kurzbehandlung
ZFS-Alternative: mergerfs + SnapRAID für gemischte Platten
ZFS will gleich große Platten und festen RAID-Level. Hast du einen Mix aus 2-, 4- und 8-TB-Platten oder willst später einzelne Disks tauschen, ist mergerfs + SnapRAID flexibler. mergerfs fasst mehrere Einzelplatten zu einem Laufwerk zusammen, SnapRAID liefert die Parität.
SnapRAID berechnet die Parität auf Abruf, nicht in Echtzeit:
snapraid sync
snapraid status
text
Files: 84211
Parity: 2 disks, 8 TB
The oldest block was scrubbed 0 days ago, the median 0.
No error detected.
Der Nachteil: SnapRAID schützt nur bis zur letzten Sync-Ausführung. Dateien, die seit dem letzten sync neu sind, sind bei einem Plattenausfall nicht durch Parität gedeckt. Für selten geänderte Mediensammlungen ist das ideal — für aktive Datenbanken nimm ZFS.
FIX 11 — Raspberry Pi 5 NAS: USB-Bandbreite messen
Raspberry Pi 5 als NAS: das USB-Bandbreitenlimit
Der Pi 5 hat keine SATA-Ports. Du hängst Platten per USB an — und teilst dir dort die Bandbreite. Miss den realen Durchsatz einer USB-Platte direkt:
hdparm -t /dev/sda
text
/dev/sda:
Timing buffered disk reads: 1098 MB in 3.00 seconds = 365.93 MB/s
Eine einzelne SSD an USB 3.0 erreicht so rund 360 MB/s. Hängst du aber mehrere Platten an denselben USB-Controller, bricht das ein, weil sich alle Geräte einen Bus teilen. Teste beide Platten gleichzeitig:
hdparm -t /dev/sda & hdparm -t /dev/sdb & wait
text
/dev/sda: Timing buffered disk reads: 590 MB in 3.01 sec = 196.01 MB/s
/dev/sdb: Timing buffered disk reads: 580 MB in 3.02 sec = 192.05 MB/s
Der Durchsatz pro Platte halbiert sich fast. Für ein NAS mit 2–4 Platten ist der Pi 5 deshalb nur bedingt geeignet. Ein N100-Board mit echten SATA-Ports liefert hier konstant volle Geschwindigkeit pro Platte.
OMV: Compose-Plugin Schritt für Schritt aktivieren
Das Compose-Plugin ist in OMV nicht ab Werk aktiv. So schaltest du es frei:
In der OMV-Weboberfläche links auf System → Plugins klicken.
In der Liste openmediavault-compose suchen, anhaken und auf Installieren klicken.
Nach der Installation erscheint links unter Dienste → Compose ein neuer Eintrag.
Unter Compose → Einstellungen legst du den Pfad für Daten und Dateien fest, z.B. /mnt/tank/appdata und /mnt/tank/compose. Auf Speichern und die gelbe Banner-Meldung mit Übernehmen bestätigen.
Prüfe in der Shell, ob das Plugin und Docker korrekt laufen:
dpkg -l | grep openmediavault-compose
docker compose version
text
ii openmediavault-compose 7.2.4 all OpenMediaVault compose plugin
Docker Compose version v2.24.5
Unter Dienste → Compose → Dateien legst du nun per + Add eine neue Stack-Datei an, fügst dein YAML ein und startest sie mit dem Up-Button.
FIX 13 — Lesbarkeit: „Aus der Praxis“-Absätze kürzen
| Unraid: Keine weiteren Festplatten zum Array hinzufügbar, GUI zeigt ‚Disk slots available: 0‘ | In der GUI unter Tools → Registration den Lizenzstatus prüfen | Lizenz zeigt z.B. „Basic“ mit Limit 6 Geräten, alle Slots belegt | Unraid-Lizenz limitiert die Anzahl der Array-Geräte: Basic = 6, Plus = 12, Pro/Unleashed = unbegrenzt. Auch Parity- und Cache-Geräte zählen mit | Array stoppen, dann auf eine höhere Lizenzstufe upgraden (Tools → Registration → Upgrade Key). Alternativ vorhandene Platten durch größere ersetzen statt neue Slots zu belegen |
| Proxmox: PCI-Passthrough scheitert mit ‚No IOMMU detected‘ oder ‚vfio: Failed to set iommu for container: Operation not permitted‘ | dmesg \| grep -e DMAR -e IOMMU \| grep -i enabled && find /sys/kernel/iommu_groups/ -type l \| wc -l | Erste Zeile leer = IOMMU aus; wc-Ausgabe 0 = keine Gruppen gebildet | VT-d/AMD-Vi im BIOS deaktiviert ODER intel_iommu=on fehlt in der grub-Zeile ODER HBA teilt sich die IOMMU-Gruppe mit anderen Geräten | VT-d im BIOS aktivieren. In /etc/default/grubintel_iommu=on iommu=pt ergänzen, update-grub, reboot. Bei geteilter Gruppe: pcie_acs_override=downstream,multifunction zur grub-Zeile hinzufügen, erneut update-grub und reboot |
Erscheint hier nichts, ist VT-d im BIOS noch aus oder intel_iommu=on fehlt in der grub-Zeile.
Befehl: zpool status storage
pool: storage
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
storage ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ata-WDC_WD40EFPX-1 ONLINE 0 0 0
ata-WDC_WD40EFPX-2 ONLINE 0 0 0
ata-WDC_WD40EFPX-3 ONLINE 0 0 0
ata-WDC_WD40EFPX-4 ONLINE 0 0 0
errors: No known data errors
state: ONLINE und errors: No known data errors sind die beiden Zeilen, die zählen. Der Pool ist gesund und einsatzbereit.
Schritt 2 (Ergänzung): Debian-Installer für OpenMediaVault durchlaufen
OMV 7 setzt auf Debian 12 (Bookworm) als Basis. Du installierst zuerst ein minimales Debian, dann OMV obendrauf. So gehst du vor:
Boot vom USB-Stick: Wähle im Debian-Installer Install (Text-Mode reicht).
Sprache/Tastatur: Deutsch / German. Das spart später Tipparbeit bei Umlauten.
Netzwerk: Hostname nas, Domain leer lassen. DHCP läuft automatisch — feste IP vergibst du später im OMV-Webinterface.
Root-Passwort: Setze ein starkes Passwort. Lege zusätzlich einen normalen User an (z.B. admin).
Partitionierung — der wichtigste Schritt: Wähle Geführt – gesamte Festplatte verwenden und als Ziel ausschließlich die Boot-SSD (oft /dev/sde, NICHT /dev/sda-sdd). Prüfe die Größe: Eine 256-GB-SSD darf nicht mit deinen 4-TB-Datenplatten verwechselt werden. Wähle dann Alle Dateien auf eine Partition — ein einfaches ext4-Layout genügt für OMV.
Software-Auswahl: Deaktiviere mit der Leertaste alles außer „SSH server“ und „Standard-Systemwerkzeuge“. Kein Desktop, kein Webserver — OMV bringt das selbst mit.
GRUB: Installiere den Bootloader auf dieselbe SSD (/dev/sde).
Nach dem Reboot meldest du dich per SSH an und installierst OMV:
Der Befehl gibt bei Erfolg keine Ausgabe zurück. Prüfe mit zpool status storage (siehe FIX 1).
Befehl: zfs list storage
NAME USED AVAIL REFER MOUNTPOINT
storage 384K 7.06T 219K /storage
Warum nur 7,06 TB bei 4×4 TB? Drei Effekte zusammen:
– RAIDZ2 opfert 2 von 4 Platten für Parität → netto 2×4 TB = 8 TB roh nutzbar.
– TB vs. TiB: Hersteller rechnen dezimal (4 TB = 4.000.000.000.000 Byte), ZFS rechnet binär (TiB). 8 TB entsprechen rund 7,28 TiB.
– ZFS-Reservierung & Metadaten: ZFS hält intern Slop-Space frei. Übrig bleiben die angezeigten ~7,06 TB.
Die Faustregel „~50% Nutzkapazität bei RAIDZ2 mit 4 Platten“ stimmt also auf TB-Ebene (8 von 16), der angezeigte Wert ist die binäre Realität nach Overhead.
Schritt 6 verifizieren: Hardware-Transcoding und Web-Oberfläche
So sieht die saubere Reihenfolge aus — erst der Befehl, dann die Ausgabe:
Befehl: docker compose -f /storage/docker/jellyfin/docker-compose.yml up -d
[+] Running 2/2
✔ Network jellyfin_default Created
✔ Container jellyfin Started
Befehl: docker ps --filter name=jellyfin
CONTAINER ID IMAGE COMMAND STATUS PORTS NAMES
a3f9c2e81b4d jellyfin/jellyfin:10.10.3 "/jellyfin…" Up 12 seconds (healthy) 0.0.0.0:8096->8096/tcp jellyfin
Up ... (healthy) und der gemappte Port 8096 bestätigen den Start. Ruf jetzt http://nas:8096 im Browser auf — der Einrichtungsassistent muss erscheinen.
Hardware-Transcoding (Intel N100 QuickSync) prüfen: Damit der Container die iGPU nutzen darf, muss /dev/dri durchgereicht sein.
Befehl: docker exec jellyfin ls -l /dev/dri
total 0
crw-rw---- 1 root 989 226, 0 Jan 12 10:20 card0
crw-rw---- 1 root 989 226, 128 Jan 12 10:20 renderD128
Erscheint renderD128, kann Jellyfin QuickSync ansteuern. Aktiviere danach im Dashboard unter Wiedergabe → Hardwarebeschleunigung den Modus Intel QuickSync (QSV). Spiel ein 4K-HEVC-File ab und prüfe live:
Schritt 7: Nextcloud absichern — Reverse-Proxy mit Nginx Proxy Manager
Port 443 war von Anfang an in den Netzwerk-Anforderungen eingeplant — hier nutzt du ihn. Statt Nextcloud direkt ins Internet zu stellen, setzt du einen Reverse-Proxy davor, der das TLS-Zertifikat verwaltet.
3. Proxy Host anlegen: Domain cloud.deinedomain.de, Forward-Hostname nextcloud (Container-Name), Port 80. Im Reiter SSL wählst du Request a new SSL Certificate mit Let’s Encrypt und aktivierst Force SSL + HTTP/2 Support.
4. Nextcloud auf den Proxy vorbereiten — sonst meldet es „Zugriff über vertrauenswürdige Domain“:
HTTP/2 200 plus der strict-transport-security-Header beweisen: TLS terminiert sauber am Proxy. Den Security-Scan rundest du mit dem Nextcloud-Sicherheitsscanner (scan.nextcloud.com) ab — Ziel ist Note A+.
FIX 7 — NUT: USV-Überwachung einrichten (Pflicht, kein Extra)
USV per NUT konfigurieren und Auto-Shutdown testen
ZFS verträgt einen harten Stromausfall mitten im Schreibvorgang schlecht — ohne USV riskierst du im schlimmsten Fall einen importunfähigen Pool. Deshalb ist eine USV mit USB-Anbindung und sauberem Shutdown-Trigger hier Pflicht.
4. Modus auf standalone setzen in /etc/nut/nut.conf:
MODE=standalone
5. Treiber starten und Status prüfen:
Befehl: sudo upsdrvctl start && upsc usv
battery.charge: 100
battery.runtime: 2730
input.voltage: 231.0
ups.load: 18
ups.status: OL
ups.status: OL heißt „Online“ (Netzstrom da). Bei Stromausfall wechselt es auf OB (On Battery), bei kritischem Akkustand auf LB (Low Battery) — dann triggert NUT den Shutdown.
7. Shutdown-Logik testen — ohne echten Stromausfall:
Befehl: upsmon -c fsd
Network UPS Tools upsmon 2.8.0
Signal 10: User requested FSD
FSD (Forced ShutDown) löst den kompletten Shutdown-Pfad aus. Führe das nur aus, wenn du das geplante Herunterfahren wirklich willst — es ist der echte Ernstfall-Test.
FIX 8 — SMART-Monitoring mit smartd einrichten
Festplattengesundheit überwachen und Mail-Alarm aktivieren
Ein NAS läuft 24/7 — Plattenausfälle willst du sehen, bevor der Pool degraded ist. Dafür richtest du smartd mit Test-Schedule und E-Mail-Benachrichtigung ein.
1. Pakete installieren:
sudo apt install smartmontools msmtp-mta
2. SMART am Laufwerk aktivieren und Status prüfen:
Befehl: sudo smartctl -i -H /dev/sda
Device Model: WDC WD40EFPX-68C6CN0
Serial Number: WD-WX12A3456789
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
SMART overall-health self-assessment test result: PASSED
PASSED ist gut — FAILED bedeutet akuten Handlungsbedarf.
3. /etc/smartd.conf konfigurieren (für alle 4 Platten):
# Short-Test täglich 02:00, Long-Test sonntags 03:00, Mail bei Fehler
/dev/sda -a -o on -S on -s (S/../.././02|L/../../7/03) -m admin@deinedomain.de -M exec /usr/share/smartmontools/smartd-runner
/dev/sdb -a -o on -S on -s (S/../.././02|L/../../7/03) -m admin@deinedomain.de -M exec /usr/share/smartmontools/smartd-runner
/dev/sdc -a -o on -S on -s (S/../.././02|L/../../7/03) -m admin@deinedomain.de -M exec /usr/share/smartmontools/smartd-runner
/dev/sdd -a -o on -S on -s (S/../.././02|L/../../7/03) -m admin@deinedomain.de -M exec /usr/share/smartmontools/smartd-runner
Der Cron-Ausdruck S/../.././02 bedeutet: Short-Test (S) jeden Tag um 02 Uhr. L/../../7/03 ist der Long-Test (L) jeden Sonntag (Wochentag 7) um 03 Uhr.
4. Dienst aktivieren und testen:
sudo systemctl enable --now smartd
sudo smartctl -t short /dev/sda
Befehl: sudo smartctl -l selftest /dev/sda
Num Test_Description Status Remaining LifeTime(hours)
# 1 Short offline Completed without error 00% 1247
5. Mail-Versand prüfen — sende einen Test-Alarm:
sudo smartd -q onecheck -d /dev/sda
Kommt der Test sauber an, wirst du bei einem realen Currently_Pending_Sector-Anstieg künftig per Mail gewarnt.
FIX 9 — Stromverbrauch korrekt messen (NAS, kein Laptop)
Realen Leerlauf-Verbrauch am NAS ermitteln
Die frühere powertop-Ausgabe mit „battery discharge rate“ war schlicht falsch — ein NAS-Board hat keinen Akku. Den realen Verbrauch misst du am Netz mit einem Steckdosen-Messgerät; powertop hilft beim Optimieren der C-States.
Bleibt die CPU überwiegend in C7, ist das Powermanagement aktiv — genau das willst du für niedrigen Idle-Verbrauch. Den tatsächlichen Wattwert liest du am Messgerät ab: Ein Intel-N100-NAS mit 4 HDDs liegt im Leerlauf typischerweise bei rund 22–28 W (HDDs im Spindown), unter Last je nach Platten bei 45–60 W.
Konkrete Stromkostenrechnung (Lücke aus dem Fließtext geschlossen):
Angenommen 24/7-Betrieb, Strompreis 0,35 €/kWh:
– Sparsames N100-NAS, Ø 30 W: 30 W × 24 h × 365 = 262,8 kWh/Jahr × 0,35 € = ~92 €/Jahr → 5 Jahre ~460 €
– Älteres NAS/i5-Eigenbau, Ø 70 W: 70 W × 24 h × 365 = 613,2 kWh/Jahr × 0,35 € = ~215 €/Jahr → 5 Jahre ~1.073 €
Die Differenz über 5 Jahre liegt damit bei rund 610 € — der eingangs genannte Korridor von „200–400 €“ gilt bei moderaterem Strompreis (~0,25 €/kWh) oder geringerer Wattdifferenz. Rechne immer mit deinem eigenen Tarif.
FIX 10 — TrueNAS Scale vs. Core: Migration und Feature-Flags
TrueNAS Core (FreeBSD) vs. Scale (Linux) — und der zpool upgrade-Stolperstein
Der zentrale Unterschied: Core basiert auf FreeBSD, Scale auf Debian-Linux. Scale bringt natives Docker/Kubernetes und KVM-Virtualisierung mit, Core setzt auf Jails und bhyve. iXsystems hat den Entwicklungsfokus klar auf Scale verschoben — Core erhält nur noch Wartungsupdates.
Migration Core → Scale ist als In-Place-Update möglich (ZFS-Pools sind kompatibel, da beide OpenZFS nutzen). Die kritische Warnung:
Niemals direkt nach der Migration zpool upgrade ausführen.
zpool upgrade aktiviert neue OpenZFS-Feature-Flags auf dem Pool. Danach kannst du nicht mehr zu Core zurück, falls Scale Probleme macht — ältere FreeBSD-Versionen kennen die neuen Flags nicht und verweigern den Import.
Befehl: zpool get all storage | grep feature@ | grep -v active | head
storage feature@edonr enabled local
storage feature@zstd_compress enabled local
storage feature@draid disabled local
enabled (noch nicht active) bedeutet: Das Flag ist verfügbar, aber noch nicht genutzt — ein Rollback wäre noch möglich. Erst zpool upgrade macht aus enabled ein active und schneidet die Brücke ab. Warte nach einer Migration mindestens 2–3 Wochen problemlosen Betrieb, bevor du upgradest.
TrueNAS Scale Stabilitätshinweis: Mehrere SMB-Multichannel- und iSCSI-Regressionen traten zwischen den Releases 22.12 (Bluefin) und 24.04 (Dragonfish) auf — siehe iXsystems Jira-Tickets NAS-123871 (SMB Multichannel) und NAS-124915 (iSCSI). Ab 24.10 (Electric Eel) gilt SMB-Multichannel als stabil. Prüfe vor produktivem Einsatz das Release-Changelog und die Resolved Issues deiner Zielversion.
FIX 11 — ZFS ohne ECC-RAM: Mythos vs. Realität
Ist ZFS ohne ECC-RAM gefährlich? Der „Scrub of Death“-Mythos
Kurze Antwort: ZFS ohne ECC ist nicht gefährlicher als jedes andere Dateisystem ohne ECC. Der berüchtigte „Scrub of Death“ — bei dem ein RAM-Bitfehler angeblich beim Scrub den gesamten Pool zerstört — ist ein Mythos, der von ZFS-Entwicklern (u.a. Matt Ahrens) widerlegt wurde.
Was real stimmt:
– ECC schützt alle Dateisysteme vor Bitflips im RAM, nicht nur ZFS.
– Ohne ECC kann ein Bitfehler eine Datei korrumpieren, bevor ZFS die Prüfsumme berechnet. ZFS speichert dann eine „korrekte Prüfsumme über falsche Daten“ — bemerkt den Fehler also nicht. Das passiert aber bei ext4/btrfs genauso.
– Ein Scrub liest, prüft und schreibt nur bei nachgewiesener Diskrepanz zurück. Er multipliziert keine RAM-Fehler über den ganzen Pool.
Praktische Empfehlung: Für ein produktives NAS mit wichtigen Daten ist ECC sinnvoll — nicht weil ZFS es zwingend braucht, sondern weil du dir die Datenintegrität bis ins RAM hinein wünschst. Boards mit Intel N100 unterstützen meist kein ECC; willst du ECC, brauchst du z.B. ein AM4-Board mit Ryzen Pro oder ein Xeon-/Atom-C-Board. Wer Backups nach 3-2-1 fährt, kann ZFS aber auch ohne ECC bedenkenlos einsetzen — das Backup fängt den seltenen Worst Case ab.
FIX 12 — 2,5GbE: Switch-Auswahl und Verkabelung
Welcher 2,5GbE-Switch und welches Kabel?
Damit 2,5GbE überhaupt durchläuft, müssen NIC, Switch und Kabel mitspielen. Häufig ist nicht die Karte, sondern das alte Cat-5-Kabel der Flaschenhals.
Verkabelung:
– Cat 5e reicht für 2,5GbE auf bis zu 100 m — ein Upgrade auf Cat 6 ist nicht zwingend. Nur uraltes Cat 5 (ohne „e“) kann auf längeren Strecken Probleme machen.
– Für 10GbE später bräuchtest du Cat 6 (bis 55 m) bzw. Cat 6a (100 m). Wer ohnehin neu verlegt, nimmt direkt Cat 6a als Zukunftssicherung.
Switch-Empfehlung (unmanaged, lüfterlos):
– 5-Port 2,5GbE: QNAP QSW-1105-5T oder TP-Link TL-SG105-M2 — passiv gekühlt, ~60–80 €.
– 8-Port mit 10G-Uplink: Zyxel XGS1210-12 (managed, 8×2,5G + 2×10G SFP+) — wenn du später ein 10G-Backbone planst.
Verifikation der ausgehandelten Linkrate:
Befehl: ethtool enp2s0 | grep -E "Speed|Duplex"
Speed: 2500Mb/s
Duplex: Full
Steht hier 1000Mb/s, handelt der Link nur Gigabit aus — meist liegt’s am Kabel oder am Switch-Port. Bei Realtek-NICs mit instabiler Session unter Last hilft das Anpassen des Interrupt-Coalescing:
Befehl (nachher, nach 10 min Last): ethtool -S enp2s0 | grep -i "rx_missed\|rx_fifo"
rx_missed: 1842
rx_fifo_errors: 1842
Bleiben die Counter nach dem Setzen konstant (kein weiterer Anstieg trotz Dauerlast), ist der Interrupt-Storm gebändigt und die SMB-Session bricht nicht mehr ab.
FIX 15 — OpenMediaVault vs. TrueNAS Core: Wann was?
OMV oder TrueNAS Core — der direkte Vergleich
Beide sind kostenlos, beide eignen sich fürs Heim-NAS — aber sie zielen auf unterschiedliche Nutzer.
OpenMediaVault ist Debian-basiert und betont Flexibilität. Du installierst Docker, eigene Pakete und ZFS als Plugin nach Belieben. Es fühlt sich wie ein normaler Linux-Server mit Weboberfläche an. Ideal, wenn du gelegentlich auf die Shell willst und Standardhardware (auch alte PCs) nutzt.
TrueNAS Core ist FreeBSD-basiert und ein geschlosseneres Appliance-System. ZFS ist tief integriert, die Konfiguration läuft fast vollständig über die GUI. Es ist robuster „out of the box“, aber du sollst die Shell möglichst meiden — manuelle Eingriffe können die Konfiguration durcheinanderbringen.
Entscheidungshilfe:
– Nimm OMV, wenn du Linux-vertraut bist, Docker-Container frei verwalten willst und ältere/gemischte Hardware nutzt.
– Nimm TrueNAS Core, wenn du eine wartungsarme ZFS-Appliance willst, dich nicht um den Unterbau kümmern möchtest und neuere Hardware hast.
– Für Neueinsteiger 2026 lohnt der Blick auf TrueNAS Scale (Linux statt FreeBSD) — es vereint OMVs Container-Flexibilität mit TrueNAS‘ ZFS-Integration.
FIX 16 — Jellyfin auf TrueNAS Scale (App statt Compose)
Jellyfin unter TrueNAS Scale: der App-Weg
Auf TrueNAS Scale installierst du Jellyfin nicht per docker compose, sondern über den integrierten App-Katalog (basiert auf Kubernetes/k3s). Der manuelle Compose-Weg von OMV funktioniert hier nicht direkt.
1. Dataset für Konfiguration und Medien anlegen (GUI: Datasets → Add Dataset), z.B. storage/apps/jellyfin und storage/medien.
2. App installieren: Apps → Discover Apps → Jellyfin → Install. Wichtige Felder:
– Configuration Storage: Host Path → /mnt/storage/apps/jellyfin
– Additional Storage (Medien): Host Path /mnt/storage/medien → Mount Path /media (read-only empfohlen)
– GPU Resources: Bei Intel-iGPU Intel GPU auf 1 setzen → reicht /dev/dri an den Pod durch.
3. Verifikation per CLI (Scale nutzt k3s, daher k3s kubectl):
Befehl: sudo k3s kubectl get pods -n ix-jellyfin
NAME READY STATUS RESTARTS AGE
jellyfin-7d9f8c6b5-x2k4n 1/1 READY 0 43s
1/1 READY und Running bestätigen den Start. Die GPU-Durchreichung prüfst du analog zu FIX 3:
Erscheint renderD128, steht QuickSync im Pod bereit.
Ich erstelle die fehlenden und korrigierten Inhalte. Da der Artikel inline repariert werden muss, liefere ich die korrigierten/neuen Bausteine als ersetzbare Blöcke (Pfad-Standard durchgehend: /mnt/storage/, Pool-Name storage).
TL;DR / Quick-Answer-Box (an den Anfang, direkt nach der Einleitung)
Kurzantwort: NAS selber bauen 2026 — lohnt sich das?
Ein DIY-NAS mit Intel N100, 16 GB RAM und 2× 8 TB HDD im Mirror kostet rund 450–550 € und zieht im Leerlauf ~10–14 W. Eine vergleichbare Synology DS224+ (ohne Platten) liegt bei ~350 € — aber mit schwächerer CPU und ohne ECC-Option. Selbstbau lohnt sich, wenn du Docker frei nutzen, ZFS fahren oder später aufrüsten willst. Fertig-NAS lohnt sich, wenn du minimalen Wartungsaufwand und Garantie aus einer Hand brauchst.
Schnellrezept (5 Schritte):
1. BIOS: AHCI an, Secure Boot aus, ASPM für Stromsparen prüfen
2. OpenMediaVault 7 oder TrueNAS Scale auf separate SSD installieren
3. ZFS-Pool per Disk-ID anlegen (zpool create storage mirror /dev/disk/by-id/...)
4. SMB-Freigabe + Docker (Portainer, Jellyfin, Nextcloud)
5. 3-2-1-Backup einrichten — RAID ersetzt kein Backup!
Korrigierter Beweis — AHCI korrekt aktiv (ersetzt den korrupten Block in Schritt 1)
Befehl: dmesg | grep -i ahci
[ 1.234567] ahci 0000:00:17.0: AHCI 0001.0301 32 slots 6 ports 6 Gbps 0x3f impl SATA mode
[ 1.234890] ahci 0000:00:17.0: flags: 64bit ncq sntf led clo only pio slum part deso sadm sds apst
[ 1.236012] scsi host0: ahci
[ 1.236234] scsi host1: ahci
[ 1.236401] ata1: SATA max UDMA/133 abar m2048@0x6011000000 port 0x6011000100 irq 127
[ 1.236589] ata2: SATA max UDMA/133 abar m2048@0x6011000000 port 0x6011000180 irq 127
Zeigt dmesg stattdessen ata1: SATA link down oder gar keine ahci-Zeilen, steht der Controller noch im IDE/RAID-Modus. Dann zurück ins BIOS und SATA Mode → AHCI setzen.
IOMMU enabled bestätigt VT-d — Voraussetzung für den späteren HBA-Durchstich unter Proxmox. Fehlt die Zeile, ist VT-d im BIOS deaktiviert oder das Board unterstützt es nicht.
Korrigierte Verifikation — Schritt 4 Samba (ersetzt den leeren Code-Block)
Befehl: sudo testparm -s
Load smb config files from /etc/samba/smb.conf
Loaded services file OK.
Server role: ROLE_STANDALONE
# Global parameters
[global]
log file = /var/log/samba/log.%m
logging = file
map to guest = Bad User
max log size = 1000
server min protocol = SMB3_00
server role = standalone server
server string = NAS Eigenbau
workgroup = WORKGROUP
idmap config * : backend = tdb
[medien]
path = /mnt/storage/medien
read only = No
valid users = nasuser
vfs objects = catia fruit streams_xattr
Loaded services file OK. ist das entscheidende Signal — bei Syntaxfehlern bricht testparm mit der genauen Zeilennummer ab. Anschließend Erreichbarkeit testen:
Befehl: smbclient -L //localhost -U nasuser
Sharename Type Comment
--------- ---- -------
medien Disk
IPC$ IPC IPC Service (NAS Eigenbau)
SMB1 disabled -- no workgroup available
SMB1 disabled ist gewollt — SMB1 ist seit Jahren unsicher (WannaCry-Vektor) und gehört abgeschaltet.
Befehl: docker compose -f /mnt/storage/apps/jellyfin/docker-compose.yml up -d
[+] Running 2/2
✔ Network jellyfin_default Created
✔ Container jellyfin Started
Schritt 6 verifizieren: Hardware-Transcoding und Web-Oberfläche
Befehl: docker ps --filter name=jellyfin
CONTAINER ID IMAGE STATUS PORTS
a3f9c1e22b7d jellyfin/jellyfin:10.9.11 Up 18 seconds 0.0.0.0:8096->8096/tcp
Prüfe, ob die Intel-iGPU im Container ankommt (QuickSync für Transcoding):
Befehl: docker exec jellyfin ls -la /dev/dri
crw-rw---- 1 root render 226, 0 Feb 3 14:22 card0
crw-rw---- 1 root render 226, 128 Feb 3 14:22 renderD128
Erscheint renderD128, steht QuickSync bereit. In Jellyfin dann unter Dashboard → Playback → Transcoding → Hardware acceleration: Intel QuickSync (QSV) aktivieren. Die Weboberfläche erreichst du unter http://NAS-IP:8096.
Korrigierter Schritt 7 — Nextcloud (komplett mit Verifikation)
Schritt 7: Nextcloud installieren — Trusted Domains, HTTPS und occ
Nach dem Compose-Start prüfst du zuerst, ob alle drei Container (App, DB, Redis) laufen:
NAME IMAGE STATUS PORTS
nextcloud-app nextcloud:29-fpm Up 24 seconds 9000/tcp
nextcloud-db mariadb:11 Up 25 seconds 3306/tcp
nextcloud-redis redis:7-alpine Up 25 seconds 6379/tcp
Den Status der Installation fragst du über das occ-Kommandozeilentool ab. Wichtig: occ läuft als Webserver-User, daher -u www-data:
Befehl: docker exec -u www-data nextcloud-app php occ status
installed: true und maintenance: false bestätigen einen sauberen Start. Damit der Zugriff per Hostname oder IP nicht mit „Untrusted Domain“ abgewiesen wird, trägst du deine NAS-Adresse als Trusted Domain ein:
Für HTTPS setzt du einen Reverse Proxy (Caddy oder Nginx Proxy Manager) davor — Caddy holt das Let’s-Encrypt-Zertifikat automatisch. Ohne TLS überträgst du Passwörter im Klartext, das ist im Heimnetz tolerierbar, beim Zugriff von außen aber ein No-Go.
2,5GbE-Netzwerk für den NAS-Eigenbau einrichten und messen
Die meisten N100-Boards bringen einen Intel i226-V oder Realtek RTL8125B mit 2,5GbE mit. Prüfe zuerst die ausgehandelte Geschwindigkeit:
Befehl: ethtool enp2s0 | grep -e Speed -e Duplex
Speed: 2500Mb/s
Duplex: Full
Zeigt Speed: 1000Mb/s, hängt entweder ein nur Gigabit-fähiger Switch dazwischen oder ein schlechtes Kabel (Cat5e reicht für 2,5GbE meist noch, Cat6 ist sicher). Den realen Durchsatz misst du mit iperf3 — auf dem NAS als Server, auf dem Client als Sender:
2,35 Gbit/s netto sind für 2,5GbE realistisch — der Overhead frisst die fehlenden ~150 Mbit/s. Bleibst du bei ~940 Mbit/s hängen, läuft die Verbindung physisch noch auf Gigabit.
FIX (neu) — HBA-Controller in IT-Mode flashen
LSI/Broadcom HBA in IT-Mode flashen: Schritt für Schritt
Ein HBA wie der LSI 9211-8i muss für ZFS in den IT-Mode (Initiator-Target, reines Durchreichen) statt IR-Mode (Hardware-RAID) geflasht werden. ZFS will die rohen Platten sehen — kein RAID-Layer dazwischen. Prüfe zuerst die aktuelle Firmware:
Wichtig: Nutze die P20-Firmware (Version 20.00.07.00) — die ältere P19 hat bekannte Probleme mit Plattenausfällen unter ZFS, und P21 wurde nie für den 9211 freigegeben. Notiere die SAS-Adresse vor dem Löschen, sonst startet die Karte ohne eindeutige ID.
Der Counter stieg vorher um 548 Pakete pro Minute und stoppt nach dem Fix komplett. Mach die Einstellung per /etc/network/interfaces (post-up ethtool -C ...) persistent, sonst ist sie nach dem Reboot weg.
FIX 9 (korrigiert, EIN Block) — Stromverbrauch mit powertop messen
powertop zeigt bei einem netzbetriebenen NAS keine Akku-Entladerate — der entsprechende Wert ist nur bei Laptops sinnvoll. Relevant ist die Paketauslastung der C-States:
C6 (pc6) 88.7% bedeutet: die CPU schläft im Leerlauf tief — gut für den Verbrauch. Den tatsächlichen Wandverbrauch misst du nur mit einem Steckdosen-Messgerät (z. B. ~11 W idle für N100 + 2 HDD im Spindown). Verlasse dich nicht auf softwareseitige Watt-Schätzungen — die sind beim N100 oft um Faktor 2 daneben.
FIX (neu) — ZFS ARC-Limit setzen und Beleg
ZFS belegt standardmäßig bis zu 50 % des RAMs als ARC-Cache. Bei 16 GB Gesamt-RAM willst du das oft begrenzen, damit Docker-Container Luft haben. Vorher prüfen:
Hier die ehrliche Gesamtrechnung über 5 Jahre — ohne Festplatten (die brauchst du in beiden Fällen):
Posten
DIY (N100)
Synology DS224+
Anschaffung (ohne HDDs)
~280 € (Board+CPU+RAM+Gehäuse+SSD)
~350 €
Stromkosten 5 J (12 W avg, 0,35 €/kWh)
~184 €
~215 € (14 W avg)
Software
0 € (OMV/TrueNAS)
0 € (DSM inkl.)
Aufrüstung RAM (möglich?)
ja, ~30 €
nein (DS224+ fix 2 GB, nicht erweiterbar in der Praxis)
Summe 5 Jahre
~494 €
~565 €
Fazit: Der DIY-Weg ist über 5 Jahre rund 70 € günstiger und flexibler (Docker, ZFS, RAM-Upgrade). Dafür zahlst du mit Bastelzeit und musst Updates selbst fahren. Synology punktet mit DSM, der besten NAS-Software am Markt, Mobile-Apps und Support aus einer Hand. Rechne grob: Ist dir eine Stunde Bastelzeit weniger als 70 € wert, kauf Synology. Macht dir das Setup Spaß und willst du volle Kontrolle, bau selbst.
Eine Anmerkung zu ECC: Der N100 unterstützt kein ECC-RAM. Wer ECC für ZFS will (nicht zwingend nötig, aber beruhigend), greift zu einem AM4-Board mit Ryzen 5600G oder einem gebrauchten Xeon-System — das sprengt aber Budget und Stromrahmen dieses Builds.
FAQ
Braucht ZFS zwingend ECC-RAM?
Nein. ZFS läuft auch ohne ECC stabil — der oft zitierte „Scrub of Death“ ist ein Mythos. ECC schützt vor RAM-Bitfehlern, die jedes Dateisystem treffen, ZFS macht sie nur sichtbarer. Für ein Heim-NAS mit dem N100 (kein ECC möglich) ist Non-ECC völlig akzeptabel. Wer Geschäftsdaten sichert, sollte ECC einplanen — dann aber nicht mit dem N100.
Ist RAID ein Backup?
Nein, niemals. RAID schützt nur vor Plattenausfall — nicht vor versehentlichem Löschen, Ransomware, Blitzschlag oder Diebstahl. Löschst du eine Datei, ist sie auf allen RAID-Platten gleichzeitig weg. Du brauchst zusätzlich die 3-2-1-Regel: 3 Kopien, 2 Medien, 1 Kopie außer Haus (z. B. Backblaze B2 per rclone).
Welches Betriebssystem für Einsteiger: TrueNAS Scale oder OpenMediaVault?
TrueNAS Scale ist „out of the box“ robuster und integriert ZFS plus App-Katalog am saubersten — du machst fast alles über die GUI. OpenMediaVault ist flexibler bei Docker und gemischter Hardware, verlangt aber mehr Linux-Wissen. Für reine Einsteiger 2026: TrueNAS Scale. Für Bastler mit Docker-Fokus: OMV.
Unterstützt der Intel N100 ECC-RAM?
Nein. Der N100 (Alder Lake-N) unterstützt offiziell kein ECC. Wer ECC braucht, weicht auf AMD Ryzen (5600G/5700G auf passendem Board) oder gebrauchte Xeon-/Epyc-Plattformen aus. Für die meisten Heim-NAS ist das aber kein K.-o.-Kriterium.
Wie viele Platten brauche ich für RAIDZ2?
Mindestens 4 — RAIDZ2 verträgt 2 gleichzeitige Plattenausfälle und braucht 2 Platten für Parität. Bei 4× 8 TB hast du also ~16 TB nutzbar. Für nur 2 Platten nimmst du einen Mirror (verträgt 1 Ausfall, ~8 TB nutzbar). Unter 4 Platten lohnt RAIDZ2 nicht.
Warum sollte ich den ZFS-Pool per Disk-ID statt /dev/sda anlegen?
Weil /dev/sdX beim Reboot wandern kann — aus sda wird sdc, und der Pool findet seine Platten nicht mehr. Disk-IDs unter /dev/disk/by-id/ sind an die Seriennummer gebunden und bleiben stabil. Immer mit zpool create storage mirror /dev/disk/by-id/ata-WDC... arbeiten, nie mit /dev/sda.
Was kostet ein DIY-NAS 2026 im Betrieb?
Ein N100-Build mit 2 HDD zieht im Leerlauf etwa 11–14 W. Bei 0,35 €/kWh sind das rund 34–43 € Stromkosten pro Jahr. Mit Festplatten-Spindown und tiefen C-States (siehe powertop) lässt sich das Richtung 10 W drücken.
Kann ich TrueNAS in einer VM unter Proxmox betreiben?
Ja, das ist ein beliebtes Setup — aber reiche den HBA-Controller per IOMMU-Passthrough komplett an die VM durch. ZFS will direkten Plattenzugriff; eine virtualisierte Disk (qcow2/virtio) raubt ZFS die Kontrolle über die Hardware und kann bei Stromausfall den Pool beschädigen. VT-d muss dafür im BIOS aktiv sein (DMAR: IOMMU enabled).
TrueNAS Jails vs Docker Container:… 4. April 2026 Vergleich der Virtualisierungsarchitekturen: FreeBSD Jails in TrueNAS CORE vs Docker Container in TrueNAS SCALE TrueNAS Jails vs Docker Container —…
Nginx Reverse Proxy in Raspberry Pi OS Docker… 4. April 2026 Nginx Reverse Proxy Container mit typischen Netzwerk-Verbindungsproblemen und Fehlerzuständen Ein Nginx Reverse Proxy in Docker Container nicht erreichbar zu beheben…
Home Assistant Docker Container auf Synology NAS… 3. April 2026 Komplette Anleitung für die Installation von Home Assistant als Docker Container auf Synology NAS mit allen wichtigen Konfigurationsschritten 80% der…
Synology Surveillance Station zu Frigate NVR… 4. April 2026 Sicherheitskritische Migration von Synology Surveillance Station zu Frigate NVR ohne Aufzeichnungsverlust Die Migration von Synology Surveillance Station zu Frigate NVR…
Node-RED vs Home Assistant: Die richtige… 4. April 2026 Vergleich der Benutzeroberflächen von Node-RED und Home Assistant für Smart Home Automation Die Wahl zwischen Node-RED und Home Assistant ist…
https://technikkram.net/wp-content/uploads/2026/06/img_00_hero_d6d60432595b49629ff0e15607204ae9.png10241536Peterhttps://technikkram.net/wp-content/uploads/2019/05/technikkram_transparent.pngPeter2026-06-12 16:39:382026-06-12 16:39:38NAS selber bauen 2026: Die vollständige Anleitung für dein Heimnetz-NAS
0Kommentare
Hinterlasse einen Kommentar
An der Diskussion beteiligen? Hinterlasse uns deinen Kommentar!
Sie sehen gerade einen Platzhalterinhalt von Turnstile. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Vimeo. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.











Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!