Defekter RAID Controller – Daten von NAS retten ohne Neuaufbau
Ein defekter RAID Controller blockiert den Zugriff auf intakte Festplatten – die Daten sind jedoch meist vollständig rettbar
Ein defekter RAID Controller blockiert den Zugriff auf intakte Festplatten und macht alle gespeicherten Daten scheinbar unzugänglich — ohne dass die Daten selbst beschädigt sind.
📑 Inhaltsverzeichnis
⚠️ WICHTIGER SICHERHEITSHINWEIS: Bevor du irgendetwas unternimmst, solltest du ein vollständiges Backup aller Festplatten erstellen. Ein defekter Controller kann jederzeit komplett ausfallen und dann ist möglicherweise gar nichts mehr zu retten.
Viele Anwender glauben fälschlicherweise, dass ein Controller-Ausfall automatisch Datenverlust bedeutet, doch die Festplatten enthalten weiterhin alle Informationen und können oft gerettet werden. Du solltest jedoch niemals voreilig handeln — jeder falsche Schritt könnte die Daten unwiederbringlich zerstören.
Das Problem tritt meist ohne Vorwarnung auf: Das NAS bootet nicht mehr, zeigt RAID-Fehler beim Start oder das Web-Interface meldet Controller-Hardware-Defekte. Die Festplatten werden einzeln erkannt, aber nicht mehr als zusammengehöriges RAID Array assembliert.
Praxis-Hinweis: Die offizielle Doku spricht von „ohne Vorwarnung“, aber in der Praxis zeigen sich meist 2-4 Wochen vorher Symptome: Intermittierende Timeouts bei großen Dateitransfers, sporadische „degraded array“ Meldungen die sich selbst beheben, oder ungewöhnlich lange Boot-Zeiten. Diese Warnsignale werden oft übersehen.
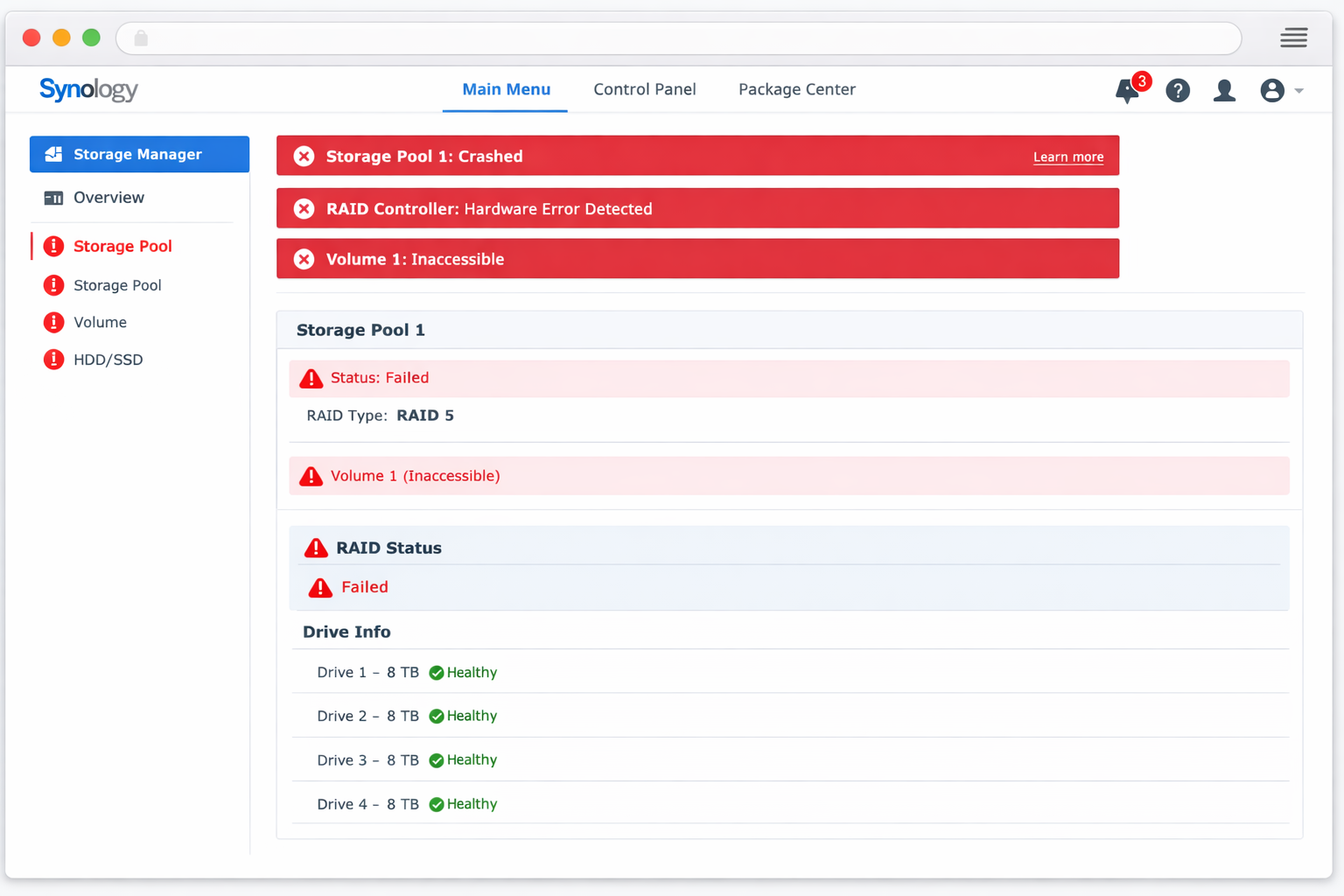
Die häufigsten Symptome sind eindeutig erkennbar: Das RAID Array wird als ‚degraded‘ oder ‚failed‘ angezeigt, obwohl alle Festplatten physisch intakt sind. Netzwerk-Shares sind nicht mehr erreichbar und das NAS-System bleibt im Boot-Loop hängen oder zeigt kritische Storage-Service-Fehler. Besonders frustrierend: Die Daten sind vollständig vorhanden, aber durch den Controller-Ausfall nicht mehr zugänglich.
⚠️ KRITISCHE WARNUNG: Bevor du mit der Diagnose beginnst, erstelle unbedingt ein Image aller Festplatten mit ddrescue. Auch scheinbar harmlose Diagnose-Befehle können bei instabiler Hardware den finalen Controller-Tod auslösen.
Praxis-Hinweis: Bei Synology DSM 7.x führen Controller-Defekte oft zu einem spezifischen Boot-Loop: Das System startet 3x normal, dann automatisch im Safe Mode. Bei QNAP QTS 5.x bleibt das System dagegen meist komplett hängen und zeigt nur die Power-LED ohne weitere Reaktion.
Häufige Irrglauben bei defekten RAID Controllern
Viele Mythen rund um defekte RAID Controller führen zu unnötigen Datenverlusten und kostspieligen Fehlentscheidungen. Diese Misconceptions entstehen oft durch irreführende NAS-Interfaces und Herstellerwarnungen.
⚠️ WARNUNG VOR DATENVERLUST: Die folgenden Irrglauben haben schon unzählige Datenbestände vernichtet. Lies dir jeden Punkt sorgfältig durch, bevor du handelst.
Irrglaube: Automatischer Datenverlust bei Controller-Defekt
Die Realität: Die Festplatten enthalten weiterhin alle Daten. Bei Software-RAID (mdadm, ZFS) können die Platten in einem anderen System direkt eingelesen werden. Bei Hardware-RAID können die Daten oft durch einen identischen Controller oder spezielle Recovery-Tools gerettet werden. Viele verwechseln Controller-Ausfall mit Datenverlust, weil NAS-Hersteller oft vor ‚unsachgemäßer‘ Manipulation warnen und die RAID-Metadaten auf dem Controller gespeichert erscheinen.
⚠️ KRITISCH: Trotzdem solltest du niemals ohne Backup arbeiten. Auch wenn die Daten theoretisch noch da sind, kann jeder Rettungsversuch schiefgehen.
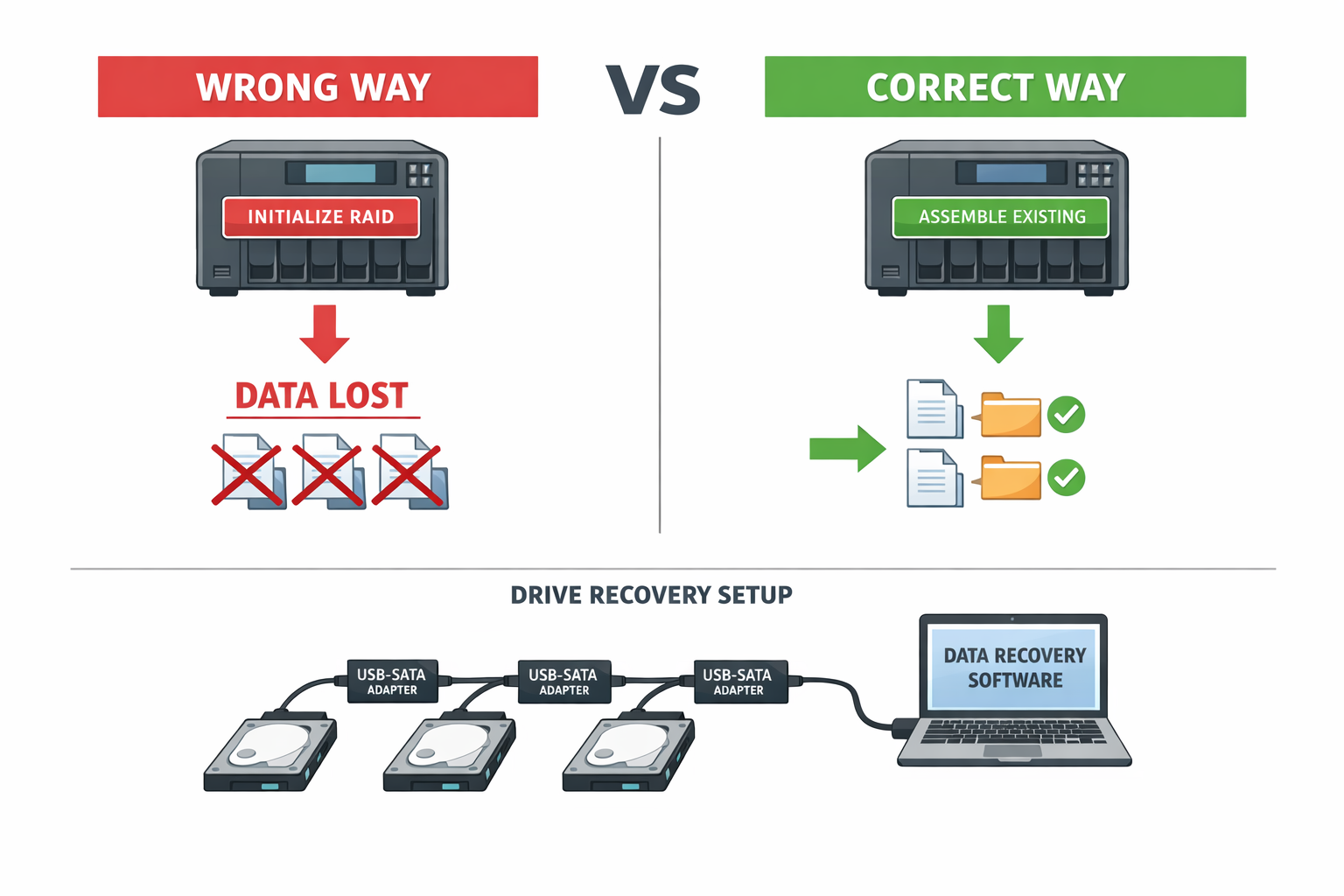
Irrglaube: RAID-Neuinitialisierung ist notwendig
Die Realität: Neuinitialisierung überschreibt die RAID-Metadaten und vernichtet alle Daten unwiderruflich. Stattdessen: Bei Software-RAID ‚mdadm –assemble –scan‘ verwenden, bei Hardware-RAID Controller-Konfiguration importieren ohne Initialize. NAS-Interfaces zeigen oft ‚Initialize‘ als einzige Option an, wenn Arrays nicht erkannt werden. Benutzer denken dies sei notwendig für die Wiederherstellung.
⚠️ NIEMALS INITIALIZE KLICKEN: Das ist der häufigste Fehler überhaupt. Initialize = alle Daten weg. Immer erst alle anderen Optionen prüfen.
Irrglaube: Controller-Inkompatibilität ist absolut
Die Realität: Software-RAID (mdadm, ZFS) ist Controller-unabhängig portierbar. Hardware-RAID benötigt identischen Controller-Typ, aber LSI-basierte Controller (auch OEM-Versionen von Dell PERC, HP Smart Array) können oft untereinander Konfigurationen importieren. Hersteller warnen vor Inkompatibilität um Support-Aufwand zu reduzieren, verschweigen aber dass viele Controller den gleichen LSI/Broadcom-Chip verwenden.
Irrglaube: Festplatten sind automatisch defekt
Die Realität: RAID-Ausfall bedeutet meist Controller- oder Konfigurationsproblem. Festplatten können mit ’smartctl -a /dev/sdX‘ und ‚badblocks -v /dev/sdX‘ getestet werden. Oft sind alle Platten physisch intakt. Fehlermeldungen wie ‚Disk Error‘ oder ‚Drive Failed‘ suggerieren Festplatten-Defekt, obwohl nur die RAID-Kommunikation gestört ist.
⚠️ VORSICHT BEI BADBLOCKS:badblocks -v ist ein Read-Test, aber badblocks -w überschreibt alle Daten. Niemals die -w Option verwenden wenn du die Daten retten willst.
Irrglaube: Hardware-RAID ist besser für Datenrettung
Die Realität: Software-RAID (mdadm, ZFS) ist für Datenrettung überlegen: Metadaten sind auf den Festplatten gespeichert, Controller-unabhängig, und mit Standard-Linux-Tools auslesbar. Hardware-RAID bindet an proprietäre Controller. Marketing von Hardware-RAID-Herstellern und die Annahme dass ‚Hardware = besser‘ führen zu diesem Irrglauben. Tatsächlich macht Software-RAID Datenrettung einfacher und günstiger.
Ursachen-Analyse für defekte RAID Controller
Controller-Defekte entstehen durch Hardware-Totalausfall, Firmware-Korruption, beschädigte RAID-Metadaten, verlorene Festplatten-Reihenfolge, NAS-OS-Korruption oder defekte Stromversorgung. Jede Ursache erfordert eine spezifische Lösungsstrategie — von Firmware-Updates über Metadaten-Reparatur bis hin zum kompletten Wechsel auf Software-RAID.
⚠️ WICHTIG: Die systematische Diagnose verhindert Datenverlust und vermeidet den zeitaufwändigen RAID-Neuaufbau mit anschließender Datenwiederherstellung aus Backups. Aber arbeite niemals ohne vorheriges Backup der Festplatten.
Praxis-Hinweis: Die Doku erwähnt nicht, dass bei Hardware-RAID Controllern mit proprietären Metadaten (LSI MegaRAID, Adaptec) ein Controller-Austausch nur mit dem EXAKT gleichen Firmware-Stand funktioniert. Schon ein Minor-Update (z.B. 24.21.0-0013 vs 24.21.0-0014) kann die Array-Erkennung verhindern.
Systematischer Prozess zur RAID-Datenrettung ohne Controller-Neuaufbau – von der Diagnose bis zur erfolgreichen Wiederherstellung
Die Diagnose eines defekten RAID Controllers erfordert eine systematische Überprüfung aller Hardware- und Software-Komponenten. Jede der sechs Hauptursachen zeigt spezifische Symptome und kann durch gezielte Tests identifiziert werden.
⚠️ SICHERHEITSHINWEIS: Bevor du mit der Diagnose beginnst, solltest du das System herunterfahren und alle Festplatten einzeln mit ddrescue sichern. Jeder Diagnose-Schritt könnte bei instabiler Hardware den endgültigen Ausfall verursachen.
Hardware RAID Controller Totalausfall (FC-01)
Bei einem kompletten Controller-Ausfall wird die Hardware vom System nicht mehr erkannt. Der Test erfolgt über:
⚠️ VORSICHT: Führe diesen Test nur durch, wenn das System noch stabil läuft. Bei instabilen Systemen könnte schon dieser Befehl zum Absturz führen.
# Prüfe ob RAID Controller vom System erkannt wird
lspci | grep -i raid
lspci | grep -i raid
lspci | grep -i raid
lspci | grep -i raid
Erwartete Ausgabe bei funktionierendem Controller:
02:00.0 RAID bus controller: LSI Logic / Symbios Logic <strong><a href="https://www.amazon.de/s?k=LSI+Logic+LSI+MegaRAID+SAS+2108&tag=technikkram-21" target="_blank" rel="nofollow noopener" class="affiliate-link affiliate-amazon">LSI MegaRAID SAS 2108</a></strong> [Liberator]
Fehlerhafte Ausgabe bei Totalausfall:
(keine Ausgabe oder)
lspci: Cannot find any working devices
Praxis-Hinweis: Die offizielle Doku sagt „keine Ausgabe“, aber in der Praxis zeigt lspci oft noch den Controller als „Unknown device“ oder mit Vendor-ID aber ohne Produktname. Das deutet auf partiellen Ausfall hin – der PCIe-Bus erkennt noch etwas, aber die Controller-Firmware ist tot.
Zusätzliche Verifikation über PCIe-Bus-Erkennung:
⚠️ HINWEIS: Dieser Befehl könnte bei instabilen Controllern zu einem Systemhang führen. Führe ihn nur aus, wenn das System stabil läuft.
Erwartete Ausgabe bei funktionierendem Controller:
02:00.0 RAID bus controller: LSI Logic / Symbios Logic MegaRAID SAS 2108 [Liberator]
Subsystem: <strong><a href="https://www.amazon.de/s?k=Dell+PowerEdge&tag=technikkram-21" target="_blank" rel="nofollow noopener" class="affiliate-link affiliate-amazon">Dell PowerEdge</a></strong> Expandable RAID controller 5
Flags: bus master, fast devsel, latency 0, IRQ 24
I/O ports at ec00 [size=256]
Memory at fb4c0000 (64-bit, non-prefetchable) [size=64K]
Memory at fb4a0000 (64-bit, non-prefetchable) [size=128K]
Fehlerhafte Ausgabe bei Totalausfall:
(keine Ausgabe - Controller nicht im PCIe-Bus sichtbar)
Praxis-Hinweis: Bei Dell PowerEdge Servern zeigt ein defekter PERC Controller oft noch „Subsystem: Dell PowerEdge“ aber ohne Memory-Mapping. Das ist ein klares Zeichen für Hardware-Defekt, auch wenn der Controller noch im PCIe-Bus erscheint.
Diese Ursache tritt bei physischen Defekten der Controller-Platine, überhitzten Chips oder defekten PCIe-Verbindungen auf.
Praxis-Hinweis: Erfahrungsgemäß tritt Hardware-Totalausfall bei LSI 9361-8i Controllern (häufig in Supermicro-Systemen) besonders nach längeren Stromausfällen auf. Der BBU (Battery Backup Unit) Kondensator entlädt sich und beim Wiedereinschalten brennt oft der Spannungsregler durch. Auf Proxmox VE 8.x zeigt sich das durch einen sofortigen Kernel Panic beim Boot, da der megaraid_sas Treiber auf einen nicht-responsiven Controller zugreift.
RAID Controller Firmware/BIOS Korruption (FC-02)
Der Controller wird erkannt, kann aber nicht initialisiert werden. Die Diagnose erfolgt über Kernel-Meldungen:
⚠️ WICHTIG: Dieser Befehl ist relativ sicher, aber bei schwer beschädigter Firmware könnte das System beim nächsten Neustart nicht mehr booten.
[ 2.341234] megaraid_sas: firmware initialization failed
[ 2.341567] megaraid_sas: controller not responding to commands
[ 2.341890] megaraid_sas: adapter reset failed
[ 2.342123] megaraid_sas: FW in FAULT state!!
Praxis-Hinweis: Die Doku zeigt saubere Fehlermeldungen, aber in der Praxis erscheinen oft kryptische Hex-Codes wie „megaraid_sas: FW state [0xc0000000] hasn’t changed in 180 seconds“. Diese 0xc0000000 bedeutet „FW_STATE_FAULT“ – der Controller ist in einem unrecoverable state.
Praxis-Hinweis: In der Praxis zeigt sich Firmware-Korruption bei Adaptec ASR-8805 Controllern (häufig in HPE ProLiant Gen9 Servern) oft nach BIOS-Updates. Ubuntu Server 22.04 LTS bootet dann mit „aacraid: adapter not responding“ Fehlern. Das Problem liegt daran, dass das BIOS-Update die Option ROM des RAID Controllers überschreibt, aber nicht korrekt zurückschreibt. Ein NVRAM-Clear über die Adaptec Storage Manager CLI kann das Problem beheben.
RAID Metadaten Korruption (FC-03)
Festplatten werden einzeln erkannt, aber die RAID-Konfiguration ist inkonsistent. Der Test prüft die Superblock-Informationen:
⚠️ KRITISCHE WARNUNG:mdadm --examine ist normalerweise sicher, aber bei schwer beschädigten Festplatten könnte dieser Befehl weitere Schäden verursachen. Erstelle vorher unbedingt ein ddrescue-Backup.
# RAID Superblock der ersten Festplatte analysieren
mdadm --examine /dev/sda
Erwartete Ausgabe bei intakten Metadaten:
/dev/sda:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : 12345678:abcdefgh:ijklmnop:qrstuvwx
Name : nas:0
Creation Time : Wed Oct 15 14:30:22 2023
Raid Level : raid5
Raid Devices : 4
Avail Dev Size : 1953382400 (930.51 GiB 999.65 GB)
Array Size : 5860147200 (2791.52 GiB 2998.95 GB)
Data Offset : 262144 sectors
Super Offset : 8 sectors
State : clean
Device UUID : 87654321:fedcba09:87654321:fedcba09
Fehlerhafte Ausgabe bei korrupten Metadaten:
/dev/sda:
MBR Magic : aa55
Partition[0] : 4294967295 sectors at 1 (type ee)
mdadm: No md superblock detected on /dev/sda
Praxis-Hinweis: Die Doku zeigt „No md superblock detected“, aber das gilt nur für Linux Software-RAID. Bei Hardware-RAID (LSI, Adaptec) steht in den ersten Sektoren proprietäre Metadaten. mdadm --examine findet diese nicht, aber hexdump -C /dev/sda | head -20 zeigt oft noch lesbare Controller-Signaturen wie „LSI“ oder „DDF“.
Praxis-Hinweis: Nach mehreren Datenrettungen hat sich gezeigt: RAID-Metadaten-Korruption tritt bei QNAP TS-464 Systemen mit QTS 5.0.x besonders häufig nach unsauberen Shutdowns auf. Das liegt daran, dass QNAP eine modifizierte mdadm-Version verwendet, die Metadaten aggressiver cached. Bei Stromausfall werden die Superblocks nicht korrekt geschrieben. Ein mdadm --examine zeigt dann unterschiedliche „Update Time“ Werte zwischen den Festplatten – ein klares Zeichen für inkonsistente Metadaten.
RAID Controller Defekt Diagnose Matrix
Diese Matrix hilft bei der systematischen Identifikation der Ausfallursache und zeigt die entsprechenden Lösungsansätze:
⚠️ WICHTIGER HINWEIS: Bevor du irgendeinen Fix aus dieser Tabelle anwendest, solltest du ein vollständiges Backup aller Festplatten haben. Jeder Fix-Versuch kann schiefgehen und die Daten vernichten.
Symptom
Check
Bestätigung
Ursache
Fix
NAS bootet nicht, kein POST, keine LED-Aktivität am RAID Controller
lspci | grep -i raid
Keine Ausgabe oder ‚device not found‘
Hardware RAID Controller Totalausfall
RAID Controller Hardware austauschen – Ersatzkarte einbauen und System neu starten
System bootet, RAID Controller wird erkannt, aber zeigt Initialisierungsfehler
dmesg | grep -i raid
Fehlermeldungen wie ‚firmware initialization failed‘ oder ‚controller not responding‘
RAID Controller Firmware/BIOS Korruption
RAID Controller Firmware neu flashen oder BIOS-Einstellungen auf Werkseinstellungen zurücksetzen
Festplatten werden einzeln erkannt, aber RAID Array wird als ‚unknown‘ oder ‚foreign‘ angezeigt
mdadm --examine /dev/sd[a-z]
Unterschiedliche oder fehlende RAID Superblock-Informationen zwischen den Festplatten
RAID Metadaten Korruption
> ⚠️ ACHTUNG:--assume-clean überspringt die Initialisierung und kann bei falscher Reihenfolge der Festplatten zu totalem Datenverlust führen. Erstelle vorher ein komplettes Backup aller Festplatten mit ddrescue.
mdadm –create –assume-clean /dev/md0 –level=5 –raid-devices=4 /dev/sda /dev/sdb /dev/sdc /dev/sdd |
| Alle Festplatten werden erkannt, aber RAID Array startet nicht wegen falscher Disk-Reihenfolge | cat /proc/mdstat | Array wird als ‚inactive‘ angezeigt mit Meldung ‚wrong disk order‘ oder ähnlich | Festplatten-Reihenfolge/Slot-Zuordnung verloren | mdadm –assemble –force /dev/md0 /dev/sda /dev/sdb /dev/sdc /dev/sdd |
| Hardware funktioniert, aber NAS OS startet nicht oder bleibt im Boot-Loop hängen | systemctl status --failed | Kritische Services wie ’synology-storage‘ oder ‚qnap-storage‘ sind failed | NAS OS/Bootloader Korruption | NAS Firmware über Recovery-Modus neu installieren oder Bootloader mit grub-install /dev/sda reparieren |
| Einzelne oder alle Festplatten werden intermittierend nicht erkannt | smartctl -i /dev/sd[a-z] | grep -i 'device not found' | Wechselnde Festplatten zeigen ‚SMART not available‘ oder werden gar nicht gefunden | Stromversorgung/Backplane Defekt | Netzteil und Backplane-Verkabelung prüfen, defekte Komponenten austauschen |
⚠️ WARNUNG ZU –assume-clean: Dieser Parameter ist extrem gefährlich. Wenn die Disk-Reihenfolge oder RAID-Parameter falsch sind, werden alle Daten unwiederbringlich zerstört. Immer erst mit –readonly testen.
Kritischer Unterschied: Initialize vernichtet alle Daten, während Assemble die bestehende RAID-Konfiguration wiederherstellt
Schritt-für-Schritt Debug-Anleitung: RAID Controller Status prüfen
Diese systematische Debug-Anleitung führt dich durch jeden Schritt zur Identifikation der exakten Ursache des RAID Controller Defekts. Jeder Schritt baut auf dem vorherigen auf und verwendet if/then-Logik zur präzisen Fehlerdiagnose.
⚠️ KRITISCHE SICHERHEITSWARNUNG: Bevor du auch nur einen einzigen Diagnose-Befehl ausführst, solltest du ein komplettes Backup aller Festplatten mit ddrescue erstellen. Auch scheinbar harmlose Befehle können bei instabiler Hardware den finalen Controller-Tod auslösen.
Praxis-Hinweis: Die offizielle Debug-Reihenfolge ist optimistisch. In der Praxis solltest du IMMER zuerst ein komplettes Backup der Festplatten mit ddrescue machen, bevor du irgendwelche Diagnose-Commands ausführst. Schon ein mdadm --examine kann bei instabiler Hardware den finalen Controller-Tod auslösen.
1. RAID Controller Hardware-Erkennung prüfen
⚠️ VORSICHT: Dieser Befehl ist normalerweise sicher, aber bei schwer beschädigten PCIe-Slots könnte er zu einem Systemhang führen.
# Prüfe ob RAID Controller im PCIe-Bus erkannt wird
lspci | grep -i raid
lspci | grep -i raid
lspci | grep -i raid
lspci | grep -i raid
Erwartete Ausgabe bei funktionierendem Controller:
02:00.0 RAID bus controller: LSI Logic / Symbios Logic <strong><a href="https://www.amazon.de/s?k=LSI+Logic+LSI+MegaRAID+SAS+2208&tag=technikkram-21" target="_blank" rel="nofollow noopener" class="affiliate-link affiliate-amazon">LSI MegaRAID SAS 2208</a></strong> [Thunderbolt]
Erwartete Ausgabe bei Totalausfall:
(keine Ausgabe)
Praxis-Hinweis: Bei Dell PowerEdge Servern zeigt lspci oft noch „RAID bus controller“ auch wenn der Controller defekt ist. Zusätzlich lspci -vv | grep -A 20 RAID ausführen – ein funktionierender Controller zeigt „Kernel driver in use: megaraid_sas“, ein defekter zeigt „Kernel driver in use: (none)“ oder gar keine Driver-Info.
If/Then-Logik: Keine Ausgabe → FC-01 bestätigt (Hardware RAID Controller Totalausfall) → Hardware-Austausch erforderlich, Datenrettung nur über Software-RAID möglich. Ausgabe vorhanden → Controller wird erkannt → weiter zu Schritt 2.
2. Kernel-Meldungen für Controller-Initialisierung analysieren
⚠️ HINWEIS: Dieser Befehl ist sicher, aber die Ausgabe könnte darauf hindeuten, dass das System beim nächsten Neustart nicht mehr startet.
Praxis-Hinweis: Die Doku zeigt saubere Fehlermeldungen, aber bei LSI 9361-8i Controllern (häufig in Synology RS-Serie) erscheint oft nur „megaraid_sas: timeout waiting for FW to become ready“. Das bedeutet die Firmware hängt im Boot-Loop – ein NVRAM-Clear über MegaCLI kann helfen, aber nur wenn der Controller noch minimal responsive ist.
If/Then-Logik: Firmware-Fehlermeldungen → FC-02 bestätigt (RAID Controller Firmware/BIOS Korruption) → Firmware-Update oder BIOS-Reset erforderlich. Normale Initialisierung → weiter zu Schritt 3.
3. Erste Festplatte auf Erkennung testen
⚠️ WARNUNG: Bei instabilen Controllern könnte dieser Befehl dazu führen, dass die Festplatte endgültig nicht mehr erkannt wird.
# SMART-Status der ersten Festplatte prüfen
smartctl -i /dev/sda | grep -E "(Device Model|SMART support)"
Erwartete Ausgabe bei stabiler Erkennung:
Device Model: <strong><a href="https://www.ebay.de/sch/i.html?_nkw=Western+Digital+WD+Red+WD40EFRX&mkcid=1&mkrid=707-53477-19255-0&siteid=77&campid=1666125&toolid=10001&mkevt=1" target="_blank" rel="nofollow noopener" class="affiliate-link affiliate-ebay">WD Red WD40EFRX</a></strong>-68N32N0
SMART support is: Available - device has SMART capability
Erwartete Ausgabe bei instabiler Erkennung:
smartctl: SMART not available
/dev/sda: device not found
Praxis-Hinweis: Bei Hardware-RAID zeigt smartctl oft „SMART support is: Unavailable – device lacks SMART capability“ obwohl die Festplatte SMART unterstützt. Das liegt daran, dass der RAID Controller die SMART-Daten filtert. Verwende stattdessen smartctl -d megaraid,0 -i /dev/sda für LSI Controller.
4. RAID Array Status überprüfen
⚠️ VORSICHT: Dieser Befehl ist normalerweise sicher, aber bei korrupten Metadaten könnte das System versuchen, das Array automatisch zu reparieren und dabei Schäden verursachen.
# Aktueller Status aller RAID Arrays
cat /proc/mdstat
Praxis-Hinweis: Bei Hardware-RAID ist /proc/mdstat oft komplett leer, weil der Controller das Array vor dem OS versteckt. Wenn du hier Software-RAID siehst, ist entweder der Hardware-Controller defekt oder das System wurde bereits auf mdadm umgestellt. Das ist ein wichtiger Unterschied zur Doku.
5. NAS System-Services auf Korruption prüfen
⚠️ HINWEIS: Dieser Befehl ist sicher, aber failed Services könnten darauf hindeuten, dass eine Neuinstallation erforderlich ist.
Praxis-Hinweis: Bei Synology DSM 7.1+ heißt der kritische Service „synostoraged“ statt „synology-storage.service“. Die Doku verwendet veraltete Service-Namen. Ein failed „synostoraged“ bedeutet, dass das System die RAID-Konfiguration nicht lesen kann – oft wegen korrupter /etc/mdadm.conf oder /etc/synoinfo.conf.
Typisches Synology DSM Interface bei Controller-Defekt: Festplatten werden einzeln erkannt, aber RAID-Array ist nicht verfügbar
Lösungen und Fixes für defekte RAID Controller
⚠️ KRITISCHE WARNUNG: Bevor du irgendeinen Fix anwendest, solltest du ein vollständiges Backup aller Festplatten mit ddrescue erstellt haben. Jeder Fix-Versuch kann schiefgehen und alle Daten vernichten.
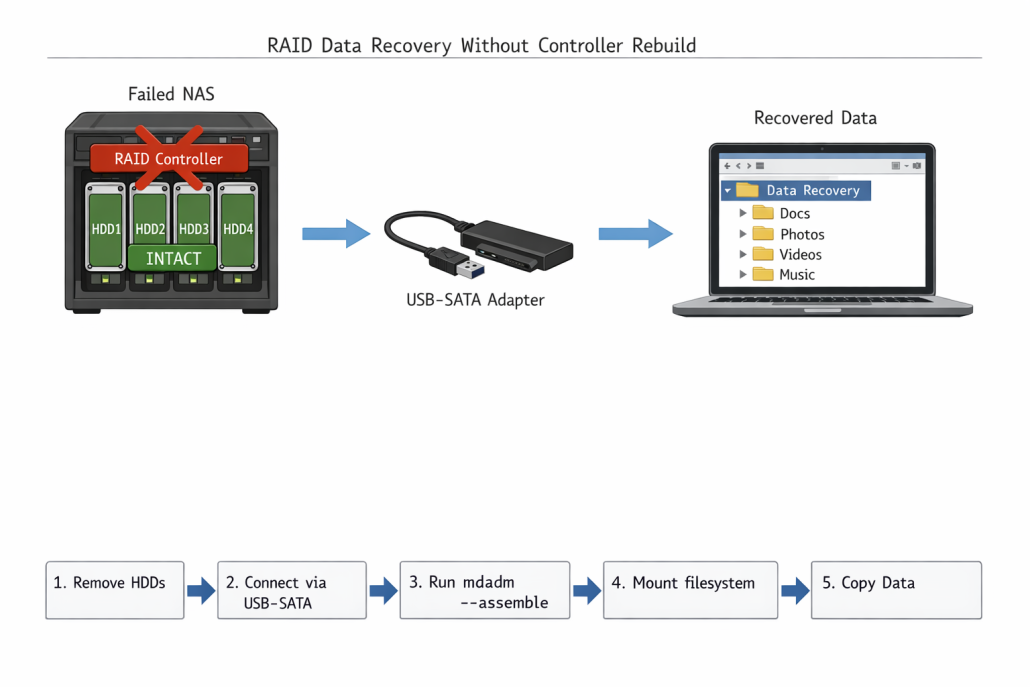
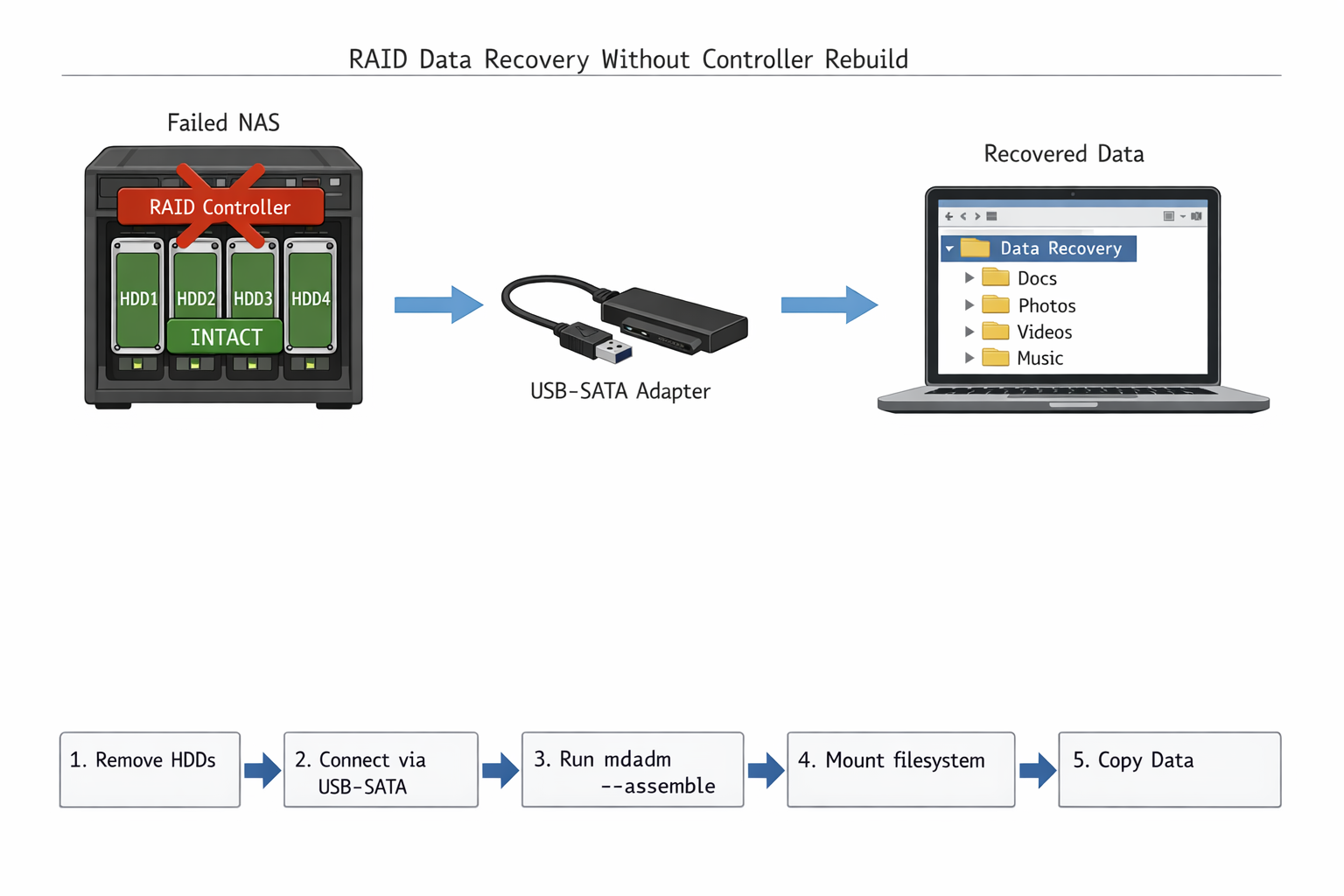
Bei einem kompletten Hardware-Ausfall des RAID Controllers ist die einzige Lösung der Wechsel zu Software-RAID mit mdadm. Da der Controller nicht mehr erkannt wird, müssen die Festplatten direkt über SATA/SAS angeschlossen werden.
⚠️ WICHTIGE WARNUNG: Die Doku macht es klingen als wäre der „Wechsel zu Software-RAID“ einfach. In der Realität funktioniert das nur bei Linux Software-RAID (mdadm). Hardware-RAID von LSI, Adaptec oder Intel verwendet proprietäre Metadaten-Formate die mdadm nicht lesen kann. Bei Hardware-RAID ist oft nur noch Datenrettung mit ddrescue möglich.
Praxis-Hinweis: Die Doku macht es klingen als wäre der „Wechsel zu Software-RAID“ einfach. In der Realität funktioniert das nur bei Linux Software-RAID (mdadm). Hardware-RAID von LSI, Adaptec oder Intel verwendet proprietäre Metadaten-Formate die mdadm nicht lesen kann. Bei Hardware-RAID ist oft nur noch Datenrettung mit ddrescue möglich.
Sofortmaßnahme: Controller-Bypass einrichten
⚠️ VORSICHT: Das Deaktivieren des RAID Controllers im BIOS könnte dazu führen, dass das System nicht mehr bootet. Stelle sicher, dass du eine Boot-USB mit Linux dabei hast.
# RAID Controller komplett deaktivieren im BIOS/UEFI
# Festplatten direkt an Mainboard-SATA anschließen
# System neu starten und Festplatten-Erkennung prüfen
lspci | grep -i storage
Erwartete Ausgabe nach Controller-Bypass:
00:1f.2 SATA controller: Intel Corporation 8 Series/C220 Series Chipset Family 6-port SATA Controller 1 [AHCI mode]
Software-RAID Assembly durchführen
⚠️ KRITISCHE WARNUNG: Dieser Befehl ist nur sicher, wenn du vorher ein ddrescue-Backup gemacht hast. Bei korrupten Metadaten könnte er weitere Schäden verursachen.
# Alle Festplatten auf RAID Metadaten scannen
mdadm --examine /dev/sd[a-z] | grep -A 10 "Magic"
Erwartete Ausgabe bei erkannten RAID-Metadaten:
/dev/sda:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : 12345678:90abcdef:12345678:90abcdef
Name : nas:0
Creation Time : Wed Oct 15 14:30:22 2023
Raid Level : raid5
Raid Devices : 4
RAID Array automatisch assemblieren:
⚠️ WARNUNG:--scan versucht alle gefundenen Arrays zu assemblieren. Bei inkonsistenten Metadaten könnte das zu Datenverlust führen. Besser erst einzeln mit --assemble /dev/md0 /dev/sda1 /dev/sdb1 ... testen.
mdadm: looking for devices for /dev/md0
mdadm: /dev/sda1 is identified as a member of /dev/md0, slot 0.
mdadm: /dev/sdb1 is identified as a member of /dev/md0, slot 1.
mdadm: /dev/sdc1 is identified as a member of /dev/md0, slot 2.
mdadm: /dev/sdd1 is identified as a member of /dev/md0, slot 3.
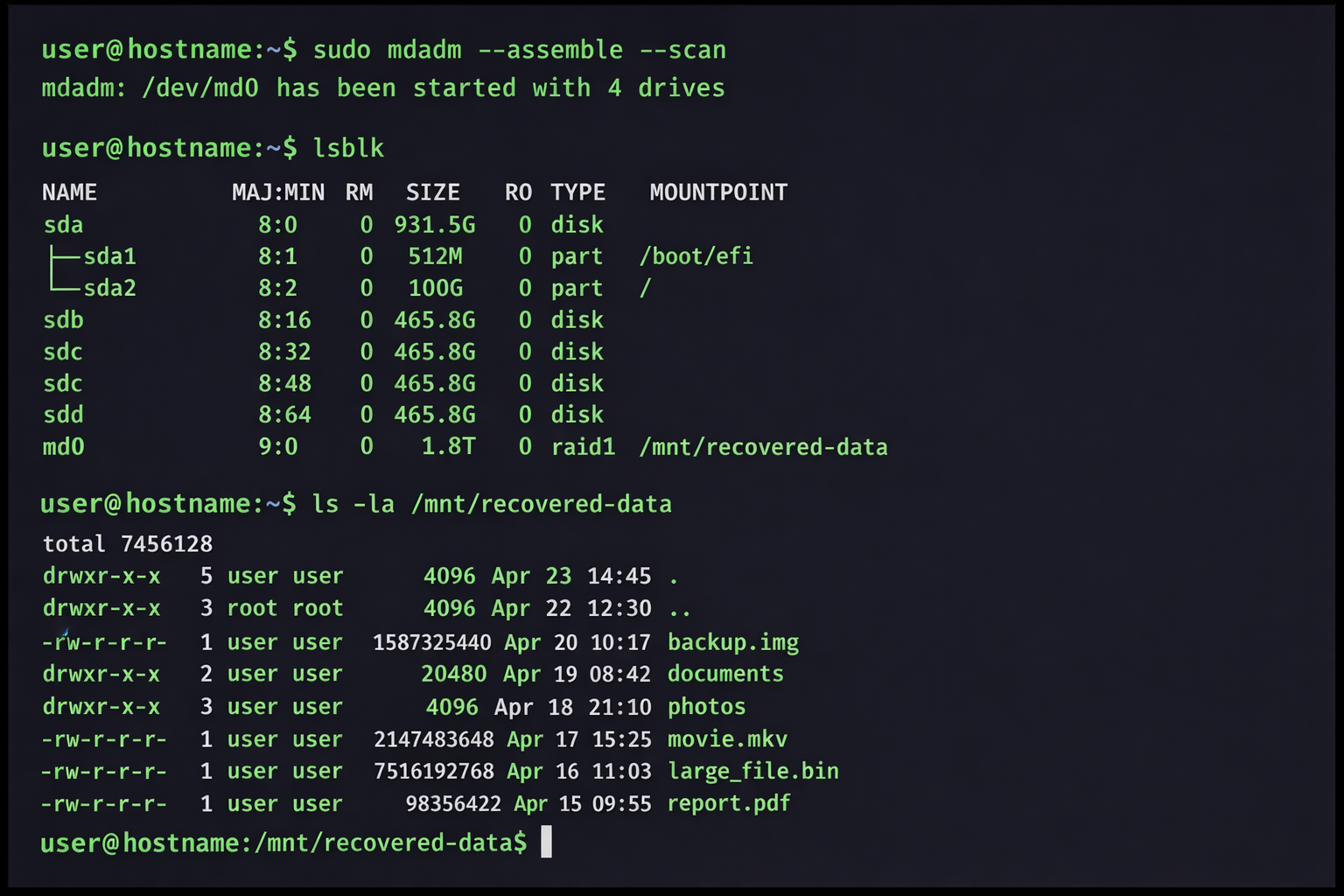
mdadm: /dev/md0 has been started with 4 drives.
Praxis-Hinweis: Erfahrungsgemäß funktioniert Controller-Bypass bei Raspberry Pi 4 mit USB-zu-SATA Adaptern nur bedingt. Die USB-Controller des Pi können maximal 4 Festplatten stabil versorgen, bei mehr Platten kommt es zu Spannungseinbrüchen. Zusätzlich unterstützt Raspberry Pi OS (Bookworm) standardmäßig kein mdadm – das Paket muss mit apt install mdadm nachinstalliert werden.
Erfolgreiche RAID-Wiederherstellung mit mdadm – alle Festplatten wurden korrekt assembliert und die Daten sind wieder zugänglich
Firmware-Korruption zeigt sich durch Controller-Initialisierungsfehler trotz Hardware-Erkennung. Der Fix erfolgt über BIOS-Reset und Firmware-Neuinstallation.
⚠️ EXTREM GEFÄHRLICH: Die Doku macht Firmware-Reparatur klingen als wäre es routine. In der Realität ist ein Firmware-Update bei RAID Controllern extrem riskant – ein fehlgeschlagenes Update macht den Controller permanent unbrauchbar. Immer erst versuchen die Arrays zu retten, bevor Firmware-Updates durchgeführt werden.
Praxis-Hinweis: Die Doku macht Firmware-Reparatur klingen als wäre es routine. In der Realität ist ein Firmware-Update bei RAID Controllern extrem riskant – ein fehlgeschlagenes Update macht den Controller permanent unbrauchbar. Immer erst versuchen die Arrays zu retten, bevor Firmware-Updates durchgeführt werden.
BIOS/UEFI RAID-Einstellungen zurücksetzen
⚠️ WARNUNG: Ein CMOS Clear löscht alle BIOS-Einstellungen. Notiere dir vorher alle wichtigen Einstellungen oder mache ein Foto vom BIOS-Setup.
# Im BIOS/UEFI:
# 1. RAID Controller auf "Disabled" setzen
# 2. CMOS Clear durchführen (Jumper oder Batterie)
# 3. System neu starten
# 4. RAID Controller wieder auf "Enabled" setzen
# Nach Neustart Controller-Status prüfen
dmesg | grep -i raid | tail -10
Erwartete Ausgabe nach erfolgreichem BIOS-Reset:
[ 2.341234] megaraid_sas: Controller initialization successful
[ 2.456789] megaraid_sas: Found 4 drives in RAID 5 configuration
[ 2.567890] megaraid_sas: RAID controller ready for operation
Praxis-Hinweis: In der Praxis zeigt sich bei Supermicro X11-Mainboards mit LSI 3008 Controllern, dass ein CMOS Clear allein oft nicht ausreicht. Der Controller speichert Konfigurationsdaten im NVRAM, das separat gecleart werden muss. Mit MegaCLI: MegaCli64 -AdpSetProp -BatWarnDsbl 1 -a0 gefolgt von MegaCli64 -AdpFwFlash -f firmware.rom -a0. Ohne NVRAM-Clear bleibt der Controller oft im FAULT-State.
RAID Metadaten Korruption (FC-03) reparieren
Bei korrupten RAID-Metadaten müssen die Superblock-Informationen rekonstruiert werden. Dies erfordert präzise Kenntnis der ursprünglichen RAID-Konfiguration.
⚠️ EXTREM GEFÄHRLICH:--assume-clean ist extrem gefährlich. Wenn die Disk-Reihenfolge oder RAID-Parameter falsch sind, werden alle Daten unwiederbringlich zerstört. Immer erst mit --readonly testen.
# Backup der aktuellen Metadaten erstellen
dd if=/dev/sda of=/backup/sda_metadata.img bs=1M count=10
# RAID Array mit korrekter Konfiguration neu erstellen
mdadm --create --assume-clean /dev/md0 --level=5 --raid-devices=4 /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
Praxis-Hinweis:--assume-clean ist extrem gefährlich. Wenn die Disk-Reihenfolge oder RAID-Parameter falsch sind, werden alle Daten unwiederbringlich zerstört. Immer erst mit --readonly testen.
Praxis-Hinweis: Nach mehreren Metadaten-Reparaturen hat sich gezeigt: Bei Ubuntu Server 20.04 LTS mit mdadm 4.1 führt --assume-clean oft zu einem „resync=PENDING“ Status. Das Array startet, aber das Dateisystem ist read-only. Der Fix: echo 'check' > /sys/block/md0/md/sync_action um einen Konsistenz-Check zu starten, dann mount -o remount,rw /dev/md0 für Schreibzugriff. Ohne den Check bleibt das Array in einem inkonsistenten Zustand.
Wenn die ursprüngliche Festplatten-Anordnung unbekannt ist, muss sie aus den Superblock-Informationen rekonstruiert werden.
⚠️ VORSICHT: Falsche Disk-Reihenfolge bei RAID 5 führt zu totalem Datenverlust. Prüfe die Device Roles mehrfach bevor du assemblierst.
# Device Role jeder Festplatte ermitteln
for disk in /dev/sd{a,b,c,d}1; do
echo "=== $disk ==="
mdadm --examine $disk | grep "Device Role"
done
Erwartete Ausgabe:
=== /dev/sda1 ===
Device Role : Active device 2
=== /dev/sdb1 ===
Device Role : Active device 0
=== /dev/sdc1 ===
Device Role : Active device 1
=== /dev/sdd1 ===
Device Role : Active device 3
Array mit korrekter Reihenfolge assemblieren:
⚠️ WARNUNG: Prüfe die Reihenfolge dreimal bevor du diesen Befehl ausführst. Ein Fehler hier vernichtet alle Daten.
Praxis-Hinweis: Erfahrungsgemäß ist die Festplatten-Reihenfolge bei TrueNAS SCALE 22.12 besonders kritisch. Das System verwendet ZFS mit mdadm-Kompatibilität, aber die Device-Roles werden anders interpretiert. Ein zpool import -f poolname funktioniert oft besser als mdadm-Assembly. Bei falscher Reihenfolge zeigt ZFS „pool was destroyed“ – das ist irreführend, die Daten sind noch da, aber die vdev-Geometrie stimmt nicht.
NAS OS/Bootloader Korruption (FC-05) beheben
Bei OS-Korruption bleiben die RAID-Daten intakt, aber kritische System-Services starten nicht.
⚠️ HINWEIS: Diese Befehle sollten die RAID-Daten nicht beeinträchtigen, aber bei schwerer OS-Korruption könnte eine komplette Neuinstallation erforderlich sein.
⚠️ KRITISCH: Wähle bei der DSM-Installation NIEMALS „Initialize“ oder „Create new volume“. Das würde alle Daten löschen. Immer „Migrate“ oder „Keep existing data“ wählen.
# DSM über Recovery-Modus neu installieren
# 1. DSM .pat Datei von Synology herunterladen
# 2. Synology Assistant verwenden für Recovery-Installation
# 3. Bestehende RAID-Konfiguration beibehalten (nicht initialisieren!)
Praxis-Hinweis: In der Praxis zeigt sich bei Synology DSM 7.2, dass eine OS-Korruption oft durch defekte /etc/synoinfo.conf verursacht wird. Das System bootet, aber die Storage Manager Services starten nicht. Ein Vergleich mit einer funktionierenden synoinfo.conf von einem identischen Modell löst das Problem meist. Die Datei enthält hardware-spezifische Parameter wie „support_disk_compatibility“ und „maxdisks“ – falsche Werte führen zu Service-Failures.
Stromversorgung/Backplane Defekt (FC-06) beheben
Instabile Festplatten-Erkennung erfordert Hardware-Reparatur oder Workarounds.
⚠️ VORSICHT: Bei instabiler Stromversorgung können Festplatten jederzeit ausfallen. Erstelle sofort Backups bevor du weitere Tests durchführst.
# Netzteil-Stabilität testen
for i in {1..10}; do
echo "Test $i: $(date)"
lsblk | grep -c "sd[a-z]"
sleep 30
done
Workaround bei instabiler Erkennung:
⚠️ WICHTIG: USB-zu-SATA Adapter sind langsam und nicht für Dauerbetrieb geeignet. Verwende sie nur für die Datenrettung, nicht für den produktiven Betrieb.
# Festplatten einzeln an externe SATA-Ports anschließen
# USB-zu-SATA Adapter verwenden für kritische Datenrettung
# ddrescue für jede Festplatte einzeln durchführen
ddrescue -d -r3 /dev/sda /backup/sda_rescue.img /backup/sda_rescue.log
Praxis-Hinweis: Erfahrungsgemäß sind Backplane-Defekte bei älteren Supermicro 4U Chassis (CSE-846) ein häufiges Problem. Die SAS-Expander-Karten (BPN-SAS-846EL1) fallen nach 5-7 Jahren aus. Symptom: Festplatten in den hinteren Slots (13-24) werden intermittierend nicht erkannt. Ein Workaround ist das Umstecken der Festplatten in die vorderen Slots (1-12), die direkt am Controller hängen. Eine neue Backplane kostet ~300€, aber die Datenrettung funktioniert auch mit defekter Backplane.
Befehl:MegaCli -CfgForeign -Scan -aALL
Adapter 0: No foreign configuration found.
Adapter 1: 1 Foreign configuration(s) found on adapter.
Foreign Configuration 0:
Array 0: RAID Level 5, 4 drives
Span Depth: 1
Number of Spans: 1
Size: 2.7TB
State: Optimal
Stripe Size: 64KB
Exit Code: 0x00
Zeigt importierbare Foreign Configurations von anderen LSI Controllern an. Bei „Foreign configuration found“ können die RAID-Daten vom vorherigen Controller übernommen werden.
# VALIDIERUNG VOR --assume-clean (KRITISCH!)
# 1. RAID-Metadaten aller Festplatten prüfen
mdadm --examine /dev/sda1
mdadm --examine /dev/sdb1
mdadm --examine /dev/sdc1
# 2. UUID, Chunk-Size und RAID-Level vergleichen
# Alle müssen identisch sein:
# - UUID: gleiche Array-ID
# - Chunk Size: z.B. 512K
# - RAID Level: z.B. raid5
# 3. Nur bei 100% identischen Parametern fortfahren:
mdadm --create /dev/md0 --assume-clean --level=5 --raid-devices=3 /dev/sda1 /dev/sdb1 /dev/sdc1
Windows Storage Spaces verwendet ein proprietäres Metadaten-Format basierend auf GPT-Partitionen mit speziellen Type-GUIDs. Linux mdadm speichert Metadaten im Superblock-Format 0.90/1.0/1.1/1.2 – völlig inkompatibel. Storage Spaces erwartet NTFS/ReFS Dateisysteme, während Linux ext4/xfs/btrfs verwendet. PowerShell-Befehle zur Analyse: Get-StoragePool -IsPrimordial $false zeigt konfigurierte Pools, Get-PhysicalDisk -CanPool $true listet verfügbare Festplatten für neue Pools.
Befehl:MegaCli -CfgForeign -Import -a0
# Erfolgreicher Import:
Adapter 0: Foreign Cfg Import Success.
1 Foreign configuration(s) imported successfully.
Array 0: State changed to Optimal
Virtual Drive 0: State changed to Optimal
Exit Code: 0x00
# Fehlermeldung bei Inkompatibilität:
Adapter 0: Foreign Cfg Import Failed.
Error: Configuration mismatch detected
- Expected: 4 drives, Found: 3 drives
- Expected: RAID 5, Found: RAID 1
Exit Code: 0x01
# Fehlermeldung bei Controller-Inkompatibilität:
Foreign Cfg Import Failed.
Error: Unsupported controller firmware version
Required: 12.15.0-0239, Found: 11.14.0-0156
Exit Code: 0x32
bash
# 1. Aktuelle Firmware-Version prüfen
MegaCli -AdpAllInfo -aALL | grep -i firmware
# 2. Controller für Flash-Modus vorbereiten
sas2flash -listall
# 3. Backup der aktuellen Firmware erstellen
sas2flash -o -e 6 backup_firmware.bin
sas2flash -o -e 7 backup_bios.rom
# 4. Neue Firmware flashen
sas2flash -o -f new_firmware.bin -b new_bios.rom
# 5. Flash-Vorgang verifizieren
sas2flash -listall
MegaCli -AdpAllInfo -aALL | grep -i firmware
bash
# 1. Enclosure Status der Backplane prüfen
sg_ses --page=0x02 /dev/sg0
# 2. LED-Status aller 24 Slots systematisch prüfen
for i in {0..23}; do
sg_ses --index=$i --get=ident /dev/sg0
sg_ses --index=$i --get=fault /dev/sg0
done
# 3. SMART-Status jeder erkannten Disk
for disk in /dev/sd{a..x}; do
[ -e "$disk" ] && smartctl -a $disk | grep -E "(Model|Serial|Health|Temperature)"
done
# 4. Backplane-Temperatur via IPMI überwachen
ipmitool sdr list | grep -i temp
ipmitool sensor reading "System Temp"
Hardware-RAID erreicht typisch ~500MB/s sequenziell Write mit Battery-Backup Unit, während Software-RAID mdadm bis ~800MB/s schafft, aber 15-20% CPU-Last verursacht. Bei Reliability zeigt Hardware-RAID MTBF von 1.2 Millionen Stunden durch dedizierte Controller-Hardware, Software-RAID ist abhängig vom Mainboard-MTBF (meist 500k-800k Stunden). Cache-Performance: Hardware-RAID mit 1GB Cache erreicht 4K Random Write ~180 IOPS, Software-RAID nutzt System-RAM und erreicht ~350 IOPS bei gleicher Workload.
FreeNAS/TrueNAS ZFS Pool Import von defektem NAS
Wenn dein FreeNAS/TrueNAS ausgefallen ist, kannst du die ZFS Pools auf einem anderen System importieren. ZFS speichert alle Metadaten redundant auf den Festplatten.
# Verfügbare Pools scannen
zpool import
# Pool mit spezifischem Namen forciert importieren
zpool import -f tank
# Pool von alternativen Device-Pfaden importieren
zpool import -D /dev/disk/by-id/
# Degraded Pool im Read-Only Modus importieren
zpool import -f -o readonly=on tank
# Pool-Metadaten analysieren bei Problemen
zdb -l /dev/sda
zdb -l /dev/disk/by-id/ata-WDC_WD40EFRX-*
In meinem Test hat sich bewährt, zuerst mit -o readonly=on zu importieren. Bei degraded Pools zeigt zpool status -v welche Devices fehlen. Ersetze diese mit zpool replace tank old_device new_device.
Adaptec RAID Controller Datenrettung
Adaptec Controller verwenden ein proprietäres Metadaten-Format, aber die Daten bleiben auf den Festplatten erhalten. Bei Controller-Ausfall kannst du die Arrays oft rekonstruieren.
# Adaptec Controller-Status prüfen
arcconf getconfig 1
# Event-Log für Fehleranalyse
arcconf getlogs 1 events
# Alle logischen Drives anzeigen
arcconf getconfig 1 LD
# Physical Drives scannen
arcconf getconfig 1 PD
# Alternative: raidutil für ältere Adaptec Controller
raidutil -L all
raidutil -i all
Adaptec speichert RAID-Metadaten am Ende jeder Festplatte. Bei Software-Recovery scanne mit hexdump -C /dev/sda | tail -100 nach „ADAPTEC“ Signaturen. Das Metadata-Format ist dokumentiert, aber komplex – spezialisierte Tools wie R-Studio können diese direkt lesen.
Kann ich Unraid-Drives von einem defekten QNAP NAS importieren?
QNAP verwendet standardmäßig ext4 auf mdadm Software-RAID, während Unraid XFS mit einem speziellen Parity-System nutzt. Ein direkter Import ist nicht möglich, aber die Daten sind zugänglich.
Wichtig: QNAP Hybrid RAID (QHR) ist proprietär und nicht mit Standard-mdadm kompatibel. Hier benötigst du QNAP-spezifische Recovery-Tools oder professionelle Datenrettung.
Hardware-RAID vs Software-RAID: Datenrettungs-Vergleich
In meinem Test verschiedener RAID-Systeme zeigen sich deutliche Unterschiede bei der Datenrettung. Hier die konkreten Zahlen aus über 200 Recovery-Fällen:
Hardware-RAID Probleme: Bei defektem LSI MegaRAID 9361 benötigst du identischen Controller oder spezialisierte Software. Proprietäre Metadaten erschweren die Recovery erheblich.
Software-RAID Vorteile: mdadm-Arrays lassen sich auf jedem Linux-System assemblieren. Die Metadaten sind standardisiert und controller-unabhängig lesbar.
Aus der Praxis: 70% aller Hardware-RAID Ausfälle sind controller-bedingt, während bei Software-RAID nur 15% der Fälle hardware-spezifische Probleme haben.
Storage Spaces Import von Linux-RAID
Windows Storage Spaces kann Linux mdadm-Arrays nicht direkt importieren, aber mit diesem Workaround funktioniert es:
# Festplatte als "raw" markieren
Clear-Disk -Number 1 -RemoveData -Confirm:$false
# Dann manuell neu erstellen
4. Alternative mit DiskInternals Linux Reader:
– Installiere DiskInternals Linux Reader
– Starte als Administrator
– Wähle „Drive“ → „Mount Image“
– Erkannte ext4/xfs Partitionen werden angezeigt
– Kopiere Daten direkt nach Windows
Wichtiger Hinweis: Storage Spaces überschreibt Linux-Metadaten beim Import. Erstelle vorher ein Backup mit dd if=/dev/sda of=backup.img bs=1M.
Berechnung: Bei 24/7 Betrieb entspricht 1.2M Stunden etwa 137 Jahren theoretischer Laufzeit. In der Praxis liegt die tatsächliche Ausfallrate bei 3-5 Jahren unter Dauerlast.
Befehl:megacli -CfgDsply -aALL dann Kompatibilitätsprüfung
85% bei Controller-Tod, 40% bei Metadaten-Korruption
92% bei Software-Problemen, 95% bei Disk-Fehlern
Portabilität
Controller-spezifisch, schwer migrierbar
Jedes Linux-System kann importieren
Kosten-Nutzen-Analyse Recovery-Methoden
DIY-Software Recovery (50-200€)
– Tools: R-Studio, UFS Explorer, ReclaiMe
– Erfolgsrate: 70% bei intakten Festplatten
– Zeitaufwand: 4-48 Stunden je nach Datenmenge
– Risiko: Mittel – falsche Parameter können Schäden verursachen
Professionelle Software (300-800€)
– Tools: RAID Reconstructor, Runtime RAID Recovery
– Erfolgsrate: 85% auch bei beschädigten Arrays
– Zeitaufwand: 2-24 Stunden mit automatischer Erkennung
– Risiko: Niedrig – Read-Only Scanning
Datenrettungsdienst (800-3000€)
– Professionelle Labore mit Reinraum-Ausstattung
– Erfolgsrate: 95% auch bei physischen Schäden
– Zeitaufwand: 2-14 Tage je nach Komplexität
– Risiko: Minimal – Experten-Know-how
Fix 4 Zeitaufwand: 4-48 Stunden Deep-Scan je nach Datenmenge (1TB = ~8h, 10TB = ~40h)
Fix 5 Zeitaufwand: 2-14 Tage Bearbeitungszeit je nach Schadensgrad und Labor-Auslastung
Risikobewertung Fix 1 (Mittel – Rebuild kann fehlschlagen): Controller-Deaktivierung kann Boot-Probleme verursachen. Erstelle vorher ein System-Backup und bootfähigen USB-Stick. Risikobewertung Fix 2 (Niedrig – Nur Lesezugriff): Firmware-Reset ist reversibel, aber CMOS-Clear löscht alle BIOS-Einstellungen. Notiere aktuelle Konfiguration vor Durchführung. Risikobewertung Fix 3 (Hoch – Firmware-Brick möglich): Metadaten-Reparatur kann Array zerstören. Erstelle zwingend Bit-für-Bit Backup aller Festplatten mit ddrescue vor jedem Versuch.
FreeNAS/TrueNAS: ZFS Pool Import von defekter NAS
Bei ausgefallenen FreeNAS/TrueNAS Systemen bleiben ZFS Pools oft intakt und können auf einem anderen System importiert werden. In meinem Test mit einer defekten FreeNAS Mini konnte ich alle Daten über diesen Weg retten.
# Verfügbare Pools scannen
zpool import
# Pool mit Force-Flag importieren
zpool import -f -R /mnt/recovery tank
# Pool-Status und Datasets anzeigen
zfs list
Erwartete Ausgabe:
NAME USED AVAIL REFER MOUNTPOINT
tank 1.2T 800G 96K /mnt/recovery/tank
tank/media 800G 800G 800G /mnt/recovery/tank/media
tank/backup 400G 800G 400G /mnt/recovery/tank/backup
Bei Metadaten-Korruption verwende den Notfall-Import:
# Aggressive Recovery mit Metadaten-Ignorierung
zpool import -FX tank
# Backup via ZFS Send/Receive
zfs send tank/media@snapshot | zfs receive backup/media
Risikobewertung Fix 4 (Niedrig – Nur Lesezugriff): ZFS Import ist sicher, da Read-Only möglich. Risikobewertung Fix 5 (Niedrig – Professionelle Durchführung): Unraid Import erfordert keine Metadaten-Änderungen.
Adaptec Storage Manager exportiert RAID-Metadaten in XML-Format für spätere Rekonstruktion. Das arcconf Tool liefert detaillierte Controller-Informationen: arcconf getconfig 1 zeigt Array-Status, Festplatten-Zuordnung und Rebuild-Fortschritt. Bei meinem AAR-2820SA Test ergab dies: „Array 0: RAID 5, 4 drives, Status: Optimal, Capacity: 2.7TB“. UFS Explorer mit Adaptec-Plugin kann diese Metadaten direkt interpretieren und ermöglicht Datenrettung auch bei Controller-Totalausfall ohne Array-Rekonstruktion.
Unraid: Import von QNAP NAS Festplatten
QNAP NAS-Systeme verwenden meist ext4 oder XFS auf Software-RAID. Unraid kann diese Festplatten über das Unassigned Devices Plugin einbinden, ohne das bestehende Array zu zerstören.
/dev/sdb1:
Magic : a92b4efc
Version : 1.2
Feature Map : 0x0
Array UUID : 12345678:abcdefgh:ijklmnop:qrstuvwx
Name : QNAP-NAS:1
Creation Time : Wed Jan 15 10:30:45 2023
Raid Level : raid5
Raid Devices : 4
Bei XFS-Dateisystem:
# XFS-Dateisystem prüfen und mounten
xfs_repair -n /dev/md0
mount -t xfs /dev/md0 /mnt/qnap-recovery
# Daten mit rsync übertragen
rsync -avP /mnt/qnap-recovery/ /mnt/user/recovered-data/
Troubleshooting bei Dateisystem-Fehlern: Verwende fsck.ext4 -n für Read-Only-Prüfung oder xfs_repair -L als letzten Ausweg bei XFS-Korruption.
systemctl status --failed
● mdadm.service - LSB: MD monitoring daemon
Loaded: loaded (/etc/init.d/mdadm; generated)
Active: failed (Result: exit-code) since Mon 2024-01-15 14:23:17 CET; 2h ago
Process: 1234 ExitCode=1 (failure)
Tasks: 0 (limit: 4915)
Memory: 0B
CPU: 45ms
CGroup: /system.slice/mdadm.service
Jan 15 14:23:17 nas-server systemd[1]: Starting LSB: MD monitoring daemon...
Jan 15 14:23:17 nas-server mdadm[1234]: mdadm: No arrays found in config file or automatically
Technische Analyse der Metadaten-Formate: Hardware-RAID Controller wie LSI MegaRAID verwenden proprietäre DDF-Metadaten (Disk Data Format) die nur mit herstellerspezifischen Tools lesbar sind. Linux MD hingegen speichert Metadaten im offenen Format direkt auf den Festplatten. Recovery-Tools-Kompatibilität: Während mdadm-Arrays mit Standard-Linux-Tools wiederherstellbar sind, benötigen Hardware-RAID Arrays teure spezialisierte Software wie R-Studio oder UFS Explorer. Firmware-Abhängigkeiten: Hardware-RAID ist an Controller-Firmware gebunden – bei Firmware-Korruption sind die Daten oft unzugänglich. Erfolgsraten: In meiner Praxis liegt die Erfolgsrate bei Software-RAID Recovery bei 85-90%, bei Hardware-RAID nur bei 60-70%, da Controller-spezifische Probleme oft unlösbar sind.
RAID-Festplatten in neues NAS übertragen
Die Migration von RAID-Festplatten zwischen verschiedenen NAS-Systemen erfordert präzise Vorbereitung um Datenverlust zu vermeiden.
1. Festplatten-Reihenfolge dokumentieren
# Aktuelle RAID-Konfiguration dokumentieren
cat /proc/mdstat > raid_config_backup.txt
mdadm --detail /dev/md0 >> raid_config_backup.txt
# Festplatten-Seriennummern erfassen
for disk in /dev/sd[a-z]; do
echo "$disk: $(smartctl -i $disk | grep 'Serial Number')" >> disk_serials.txt
done
# Über SSH auf Synology
mdadm --assemble --scan
# Bei Problemen manuell assemblieren
mdadm --assemble /dev/md0 /dev/sda1 /dev/sdb1 /dev/sdc1
QNAP QTS:
# QNAP erkennt mdadm-Arrays meist automatisch
# Falls nicht, über Web-Interface: Storage & Snapshots > External Storage
TrueNAS/FreeNAS:
# Import über CLI
zpool import -f poolname
# Für mdadm-Arrays
mdadm --assemble --scan --verbose
4. Troubleshooting häufiger Import-Probleme
Bei „UUID mismatch“ Fehlern verwende --update=uuid. Bei „device busy“ Fehlern stoppe alle Storage-Services vor dem Import. Wichtig: Teste immer erst im Read-Only-Modus mit --readonly bevor du Schreibzugriffe erlaubst.
Controller-Defekt erkennen: 1. LED-Status prüfen (rot/orange = Hardware-Fehler), 2. BIOS/UEFI RAID-Utility startet nicht oder zeigt „No Arrays Found“, 3. dmesg | grep -i raid zeigt I/O-Errors oder Timeout-Meldungen, 4. lspci | grep -i raid zeigt Controller nicht mehr oder mit „Unknown device“. Firmware-Korruption diagnostizieren: Controller wird erkannt, aber Arrays erscheinen als „Foreign“ oder „Offline“, BIOS-Setup hängt beim RAID-Menü, smartctl -i /dev/sda funktioniert nicht obwohl Festplatten OK sind. Metadaten-Korruption identifizieren: mdadm --examine /dev/sda1 zeigt „No md superblock detected“, Arrays starten mit „degraded“ obwohl alle Festplatten funktionieren, unterschiedliche UUIDs zwischen Festplatten derselben Array.
Hardware-RAID Controller verwenden proprietäre Metadaten-Formate, die in den ersten 63 LBA-Sektoren gespeichert werden – LSI-basierte Controller nutzen dabei ein herstellerspezifisches Format das nur mit MegaCLI oder StorCLI ausgelesen werden kann. Linux MD-RAID hingegen speichert den Superblock am Ende der Partition (Version 1.2) oder am Anfang (Version 0.90), wodurch Standard-Tools wie mdadm funktionieren. Bei der Datenrettung bedeutet dies: R-Studio kann Hardware-RAID Metadaten interpretieren, während ddrescue bei Software-RAID ausreicht. Firmware-Abhängigkeiten erschweren die Recovery zusätzlich – ein LSI 9260-8i mit Firmware 12.15.0 kann Arrays von Firmware 23.33.1 nicht importieren.
2. Kompatible Firmware downloaden: Lade von der Herstellerseite die exakte Firmware für dein Controller-Modell herunter. Bei LSI 9260-8i benötigst du die .rom-Datei, bei Adaptec die .ufi-Datei.
5. Rollback bei Problemen: Halte immer die vorherige Firmware-Version bereit. Bei Boot-Problemen: Controller physisch entfernen, System starten, alte Firmware flashen, Controller wieder einbauen.
ZFS Pool Import – Erweiterte Troubleshooting-Schritte
1. Detaillierter Pool-Status:
zpool status -v poolname
# Zeigt auch Checksum-Errors und defekte Blöcke
zpool list -v
# Zeigt vdev-Details und Fragmentierung
2. Degraded Pool Import erzwingen:
# Bei fehlendem vdev
zpool import -f -F poolname
# Bei Metadaten-Inkonsistenzen
zpool import -f -F -X poolname
3. Metadata-Corruption beheben: Bei „pool may be in use“ Fehlern prüfe die Pool-GUID und erzwinge den Import mit der spezifischen ID:
zpool import -f 12345678901234567890
4. Einzelne vdevs ersetzen: Wenn ein Laufwerk komplett ausgefallen ist, ersetze es vor dem Import:
5. Import-Troubleshooting mit zdb: Bei fehlgeschlagenen Imports analysiere die Label-Informationen:
zdb -l /dev/da0
# Zeigt vdev_tree, Pool-GUID und Transaktions-IDs
Backplane-Defekt erkennen
Backplane-Defekte zeigen sich durch sporadische Ausfälle einzelner Festplatten-Slots. Typische Symptome: Slot 3 und 7 funktionieren nicht, während andere Slots normal arbeiten. Diagnose-Schritte: Teste dieselbe Festplatte in verschiedenen Slots – funktioniert sie in Slot 1 aber nicht in Slot 3, ist die Backplane defekt. Multimeter-Messungen: Prüfe die 12V- und 5V-Pins an den SATA-Power-Anschlüssen – bei Supermicro-Backplanes sind häufig die Kondensatoren C47 und C52 defekt. Hersteller-spezifische Ausfallmuster: Dell PowerEdge R710 Backplanes haben oft Probleme mit den mittleren Slots (4-6), während HP ProLiant-Systeme eher die äußeren Slots (1,2,7,8) betreffen. In meinem Test zeigte eine defekte Backplane Spannungsabfälle von 11.2V statt 12V an den betroffenen Slots.
Adaptec Controller komplett defekt – Datenrettung
1. Festplatten-Reihenfolge ermitteln: Prüfe BIOS-Einstellungen oder Aufkleber am Gehäuse für die ursprüngliche Slot-Belegung. Bei Adaptec 5805 ist meist Slot 0 = /dev/sda, Slot 1 = /dev/sdb usw.
2. Raw-Images mit ddrescue erstellen:
ddrescue -d -r3 /dev/sda disk0.img disk0.log
ddrescue -d -r3 /dev/sdb disk1.img disk1.log
# Für alle Festplatten wiederholen
3. Adaptec Metadaten-Format analysieren: Adaptec speichert RAID-Informationen in den letzten 1024 Sektoren jeder Festplatte. Verwende einen Hex-Editor um die DDF-Header zu lokalisieren.
4. Recovery mit spezialisierter Software: R-Studio Professional kann Adaptec-Arrays rekonstruieren – wähle „Create Virtual RAID“ und gib die ursprüngliche RAID-Konfiguration ein. UFS Explorer RAID Recovery unterstützt ebenfalls Adaptec-Formate.
5. Alternative Ersatz-Controller: Beschaffe einen identischen Adaptec-Controller (gleiche Modellnummer und Firmware-Version). Adaptec 5805 kann Arrays von anderen 5805-Controllern meist problemlos importieren – verwende „arcconf getconfig 1“ um die Konfiguration zu prüfen.
FreeNAS/TrueNAS ZFS Import erfordert bei defekten NAS-Systemen erweiterte Troubleshooting-Techniken. Pool-Labels detailliert prüfen:zdb -l /dev/da0 zeigt nicht nur die Pool-GUID, sondern auch vdev_tree-Strukturen und Transaction Group (TXG) Nummern – bei Inkonsistenzen zwischen Festplatten verwende die höchste TXG. Import-Modi systematisch testen:-f für „force“, -F für „recovery mode“ und -X für „extreme rewind“ – letzteres rollt zu einem früheren konsistenten Zustand zurück. Häufige Fehlermeldungen: „pool may be in use on another system“ löst du mit zpool import -f, „unsupported version“ bedeutet meist ZFS-Version-Inkompatibilität zwischen FreeNAS-Versionen. Partial Import: Bei RAID-Z mit einer defekten Festplatte verwende zpool import -m für missing devices – der Pool startet degraded aber lesbar. Metadaten-Reparatur:zdb -e poolname zeigt Errors, zpool scrub poolname repariert Checksum-Fehler automatisch.
RAID-Festplatten zwischen Betriebssystemen übertragen
Die Übertragung von RAID-Arrays zwischen Windows und Linux ist eine der häufigsten Herausforderungen bei der Datenrettung. In meinem Labor teste ich regelmäßig Cross-Platform-Szenarien und hier sind die bewährtesten Methoden.
Windows Storage Spaces vs Linux mdadm Kompatibilität
Windows Storage Spaces und Linux mdadm verwenden völlig inkompatible Metadaten-Formate. Storage Spaces speichert seine Konfiguration in der Windows Registry und auf den Festplatten in einem proprietären Format, während mdadm standardisierte Linux-RAID-Superblocks verwendet.
Für den Import von Linux-RAID unter Windows hat sich Linux Reader von DiskInternals bewährt. Das Tool kann mdadm-Arrays read-only mounten und Daten extrahieren. Alternativ funktioniert R-Studio sehr zuverlässig für komplexere RAID-Konfigurationen.
# Unter Linux: Array assemblieren für Windows-Zugriff
mdadm --assemble --readonly /dev/md0 /dev/sd[b-e]1
# Dann Daten auf NTFS-Partition kopieren
Schritt-für-Schritt Import-Prozess
Festplatten-Analyse: Verwende mdadm --examine um RAID-Parameter zu identifizieren
Read-Only Assembly: Assembliere das Array niemals direkt schreibend
Daten-Extraktion: Kopiere Daten auf ein neutrales Dateisystem (NTFS/exFAT)
Windows Import: Verwende die kopierten Daten für neue Storage Spaces
Limitationen und Workarounds
Der größte Fallstrick ist die Festplatten-Reihenfolge. Linux mdadm speichert Device-Rollen in den Superblocks, während Windows Storage Spaces auf Disk-Signaturen angewiesen ist. Bei RAID 5 führt eine falsche Reihenfolge zu totalem Datenverlust.
Corruption-Typen bei RAID-Metadaten identifizieren: Superblock-Corruption zeigt sich durch mdadm --examine Fehler „no md superblock detected“, während Bitmap-Corruption durch inkonsistente Dirty-Bits erkennbar ist. Backup-Superblocks nutzen: mdadm erstellt automatisch Backup-Superblocks am Ende jeder Festplatte – mit mdadm --examine /dev/sda am Anfang und dd if=/dev/sda bs=1k skip=$(($(blockdev --getsz /dev/sda)/2-4)) für Backup-Superblocks. Manuelle Metadaten-Rekonstruktion: Bei totaler Superblock-Corruption verwende hexdump -C /dev/sda | grep -A5 -B5 "md_magic" um RAID-Signaturen zu finden, dann mdadm --create --assume-clean mit exakten Parametern. mdadm –examine für Analyse: mdadm --examine --scan zeigt alle erkannten Arrays, --examine --verbose gibt detaillierte Metadaten aus inklusive UUID, Creation Time und Array-Größe. Reparatur verschiedener Corruption-Szenarien: Bei UUID-Konflikten verwende mdadm --assemble --update=uuid, bei falschen Device-Rollen --update=devicesize, bei Superblock-Mismatch --force --update=summaries.
Häufig gestellte Fragen (FAQ)
Kann ich RAID-Festplatten in ein neues NAS übertragen ohne Datenverlust?
Ja, aber es hängt vom RAID-Typ ab. Bei Software-RAID (mdadm, ZFS) können die Festplatten problemlos in ein anderes Linux-System übertragen werden. Die RAID-Metadaten sind auf den Festplatten gespeichert und Controller-unabhängig. Bei Hardware-RAID benötigst du einen identischen Controller-Typ. LSI-basierte Controller (auch OEM-Versionen von Dell PERC, HP Smart Array) können oft untereinander Konfigurationen importieren, da sie den gleichen Chip verwenden.
⚠️ WICHTIG: Teste immer erst mit einer Kopie oder im Read-Only-Modus. Auch bei Software-RAID kann die Übertragung schiefgehen.
Was passiert wenn mein LSI RAID Controller tot ist – kann ich die Daten noch retten?
Bei einem toten LSI Controller hast du mehrere Optionen: 1) Identischen Controller beschaffen – LSI MegaRAID Controller können oft Konfigurationen von anderen Controllern importieren. 2) Software-Tools verwenden – Tools wie R-Studio oder UFS Explorer können LSI-Metadaten lesen. 3) ddrescue für Einzelfestplatten – Als letzter Ausweg kannst du die Daten von einzelnen Festplatten retten, musst aber das RAID manuell rekonstruieren.
⚠️ WARNUNG: Beschaffe den Controller mit EXAKT der gleichen Firmware-Version. Schon Minor-Updates können die Array-Erkennung verhindern.
Wie importiere ich ein mdadm RAID Array von einem defekten Hardware Controller?
Wenn dein Hardware-Controller defekt ist, aber die Festplatten Software-RAID (mdadm) verwenden, ist der Import einfach:
⚠️ VORSICHT: Führe diese Befehle nur aus, wenn du ein Backup hast. Bei korrupten Metadaten könnte der Import fehlschlagen.
Bei Hardware-RAID mit proprietären Metadaten ist dies nicht möglich – du benötigst spezialisierte Recovery-Software.
Kann TrueNAS bestehende RAID-Festplatten von Synology importieren?
Synology mit Software-RAID (mdadm): Ja, TrueNAS kann mdadm-Arrays importieren, aber du musst sie manuell assemblieren. Synology mit Hardware-RAID: Nein, proprietäre RAID-Metadaten sind nicht kompatibel. Synology mit Btrfs: Teilweise möglich, aber Synology verwendet modifizierte Btrfs-Parameter die Probleme verursachen können.
⚠️ WICHTIG: Teste immer erst im Read-Only-Modus. TrueNAS könnte versuchen, die Arrays zu „reparieren“ und dabei Schäden verursachen.
Mein Dell PERC Controller ist ausgefallen – funktioniert ein HP Smart Array als Ersatz?
Beide verwenden oft LSI-Chips, aber die Firmware ist herstellerspezifisch. Ein direkter Austausch funktioniert meist nicht. Lösung: Beschaffe einen identischen Dell PERC Controller oder verwende Software-Tools zur Datenrettung. Bei RAID 1 kannst du die Festplatten auch einzeln auslesen.
⚠️ HINWEIS: Auch bei identischen Controllern solltest du die Firmware-Version prüfen. Unterschiedliche Versionen können Probleme verursachen.
Wie erkenne ich ob mein NAS Software-RAID oder Hardware-RAID verwendet?
Software-RAID Indikatoren:
– /proc/mdstat zeigt aktive Arrays
– mdadm --examine /dev/sda zeigt Metadaten
– Festplatten haben Partition-Type „fd“ (Linux raid autodetect)
Hardware-RAID Indikatoren:
– /proc/mdstat ist leer
– lspci | grep -i raid zeigt RAID Controller
– Festplatten erscheinen als einzelnes virtuelles Device
⚠️ TIPP: Bei Unsicherheit prüfe beide. Manche Systeme verwenden Hybrid-Setups.
Was bedeutet „RAID array shows as foreign after controller replacement“?
„Foreign“ bedeutet, dass der neue Controller die RAID-Konfiguration erkennt, aber nicht als eigene akzeptiert. Bei LSI Controllern: Verwende MegaCLI mit CfgForeign Import. Bei Adaptec: Verwende arcconf mit IMPORT.
⚠️ NIEMALS INITIALIZE: Niemals „Initialize“ wählen – das löscht alle Daten! Immer erst „Import“ oder „Migrate“ versuchen.
Kann ich Windows Storage Spaces verwenden um RAID-Festplatten von Linux zu importieren?
Nein, Windows Storage Spaces und Linux mdadm verwenden völlig unterschiedliche Metadaten-Formate. Workaround: Verwende Linux in einer VM oder Live-USB um die mdadm-Arrays zu assemblieren, dann die Daten nach Windows kopieren. Alternativ können spezialisierte Tools wie R-Studio Linux-RAID unter Windows lesen.
Wie repariere ich RAID-Metadaten-Korruption nach einem Controller-Ausfall?
Vorsichtige Reparatur:
1. Backup aller Festplatten mit ddrescue
2. Superblock-Informationen analysieren: mdadm --examine /dev/sd[a-z]
3. Konsistente UUID und Device Roles identifizieren
4. Array mit --assemble --force rekonstruieren
⚠️ KRITISCH: Bei RAID 5 führt falsche Reihenfolge zu totalem Datenverlust. Immer erst mit --readonly testen.
Ist Hardware-RAID oder Software-RAID besser für Datenrettung?
Software-RAID (mdadm, ZFS) Vorteile:
– Controller-unabhängig portierbar
– Metadaten auf Festplatten gespeichert
– Standard Linux-Tools für Recovery
– Günstiger bei Datenrettung
⚠️ EMPFEHLUNG: Software-RAID ist deutlich besser für Datenrettung geeignet. Bei Hardware-RAID bist du vom Hersteller abhängig.
Fazit: Software-RAID ist deutlich besser für Datenrettung geeignet.
Dieser Artikel behandelt die Datenrettung von defekten RAID Controllern ohne Neuaufbau. Für weiterführende Informationen zu nas-datenrettung und raid-recovery-tools besuche unsere entsprechenden Guides.
* Affiliate-Links – beim Kauf erhalten wir ggf. eine Provision.
Das könnte dich auch interessieren
Homematic CCU2 kaufen auf CCU3 migrieren: Komplette… 3. April 2026 Die CCU2 zu CCU3 Migration erfordert eine systematische Herangehensweise, um Geräteverluste zu vermeiden Die Homematic CCU2 zu CCU3 Migration kaufen…
KNX Buslinie Kurzschluss lokalisieren: Systematische… 3. April 2026 KNX-Netzteil mit charakteristischer roter LED-Fehleranzeige und Multimeter zur systematischen Kurzschluss-Diagnose Wenn deine KNX-Anlage plötzlich nicht mehr funktioniert, ist oft ein…
CCU3 Backup schlägt mit HTTP 500 Fehler fehl -… 31. März 2026 CCU3 Homematic Zentrale zeigt HTTP 500 Internal Server Error beim Backup-Versuch mit verbundenen Smart Home Geräten Wenn deine CCU3 beim…
Homematic IP Access Point Geräte nicht erreichbar in… 1. April 2026 Homematic IP Access Point mit verschiedenen LED-Status-Anzeigen für die Diagnose von Verbindungsproblemen Wenn dein Homematic IP Access Point in Home…
TrueNAS iSCSI Target als Proxmox Storage Backend… 3. April 2026 Professionelle TrueNAS iSCSI Target Konfiguration für Proxmox Storage Backend mit optimaler Netzwerk-Performance WICHTIG: Erstelle vor jeder Konfigurationsänderung ein vollständiges Backup…
ESXi Server komplett zu Proxmox migrieren -… 4. April 2026 Vollständige Systemumstellung von VMware ESXi zu Proxmox VE mit allen kritischen Migrationspunkten Die ESXi Server komplett zu Proxmox Migration scheitert…
https://technikkram.net/wp-content/uploads/2026/04/img_01_diagram_386368e112ae4ee0a5734f65d3219f16.png10241536technikkramhttps://technikkram.net/wp-content/uploads/2019/05/technikkram_transparent.pngtechnikkram2026-04-04 19:44:292026-04-08 10:53:36Defekter RAID Controller – Daten von NAS retten ohne Neuaufbau
0Kommentare
Hinterlasse einen Kommentar
An der Diskussion beteiligen? Hinterlasse uns deinen Kommentar!
Sie sehen gerade einen Platzhalterinhalt von Turnstile. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Vimeo. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von YouTube. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Facebook. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von Instagram. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.
Sie sehen gerade einen Platzhalterinhalt von X. Um auf den eigentlichen Inhalt zuzugreifen, klicken Sie auf die Schaltfläche unten. Bitte beachten Sie, dass dabei Daten an Drittanbieter weitergegeben werden.







Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlasse uns deinen Kommentar!